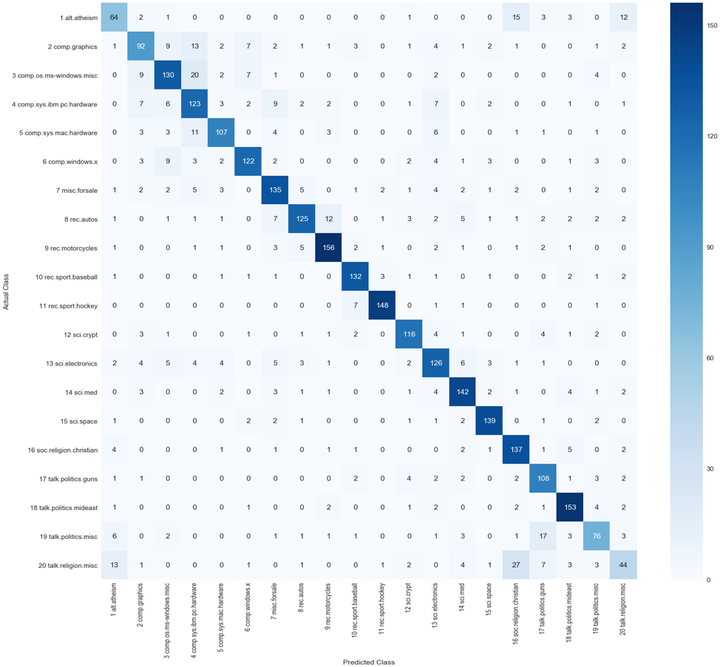
 confusion matrix
confusion matrix
Abstract: In this class project, we have implemented both Naive Bayes (NB) and Logistic Regression (LR) algorithms to classify the topic of a document based on its content (words). A total of 12,000 newsgroup documents, partitioned (nearly) evenly across 20 different newsgroups were used for training these algorithms, whereas a total of 6,774 documents were used to test the efficiencies of the two methods. The accuracies of our developed algorithms were evaluated by uploading the outputs for the testing dataset in Kaggle. The accuracies of the NB and the LR are 89.74% and 81.72% respectively without any preprocessing. We have also found that the NB is faster than the LR. In addition to using the whole dataset, we calculated the mutual information between topic (class) and each word (feature) to identify the important features in the large dataset by applying the information theory. As expected, the prepositions (“the”, “of”, “a”) score lower among the words in the documents.
Farhan Asif Chowdhury
Graduate Research Assistant
My research interests include studying the temporal dynamics of user behaviour on social networks with a focus on detecting coordinated malicious activity.