Advanced Operating Systems
- http://www.cs.unm.edu/~darnold/classes/cs587-f09/
- Office Hours: after class
Table of Contents
- Meta
- class notes
- 2009-08-25 Tue
- 2009-08-27 Thu
- 2009-09-01 Tue
- 2009-09-03 Thu
- 2009-09-08 Tue
- 2009-09-10 Thu
- 2009-09-17 Thu
- 2009-09-22 Tue
- 2009-09-24 Thu
- 2009-09-29 Tue
- 2009-10-01 Thu
- 2009-10-06 Tue
- 2009-10-08 Thu
- 2009-10-20 Tue
- 2009-10-22 Thu
- 2009-10-27 Tue
- 2009-10-29 Thu
- 2009-11-03 Tue
- 2009-11-05 Thu
- 2009-11-10 Tue
- 2009-11-12 Thu
- 2009-12-01 Tue
- 2009-12-03 Thu
- reading notes
- Map / Reduce
- peer-to-peer
- Amoeba vs. Sprite
- Network Services
- QuickSilver
- Munin DSM
- CODA
- RAID
- NFS network file system
- log file system
- fast file system
- VM in Multics
- VM in Vax
- lottery scheduling
- resource containers
- Scheduler activations
- Monitors (2)
- Virtualization
- Exokernel
- µ-kernels
- Unix Time Sharing System
- Observations on the Development of an Operating System
- Hints for Computer System Design
- project
- exams [1/3]
- question
- concepts / terms
- overview
Meta
Grade Breakdown
| 10 | participation |
| 25 | homework |
| 25 | project |
| 22.5 | midterm |
| 22.5 | final |
class notes
2009-08-25 Tue
- same course path as undergraduate OS, just much more detail
- all reading in research papers
-
groups
- all reading
- all work
- one day's lecture
-
research-lite project
- proposal in ~3rd weak of Sept.
- 1-2 month working on implementation
- will produce a research-paper
- undergrad lectures serve as good background for the course
2009-08-27 Thu
email server was down, try again or send email to Dorian
concepts
overview
- OS
-
software providing access to hardware (cpu, memory, disk, IO)
- policies
- what user can do
- mechanisms
- how policies enforced
- permission levels
-
often controlled by indicator bit
- user
- kernel
- system call
-
allows access to kernel functions from user mode
- syscall is made
- parameters stored in registers
- switch to kernel mode
- execute routine defined in the kernel
virtual memory
virtual address space which can be mapped to actual memory. this allows the process using the memory to be loaded/unloaded/moved etc…
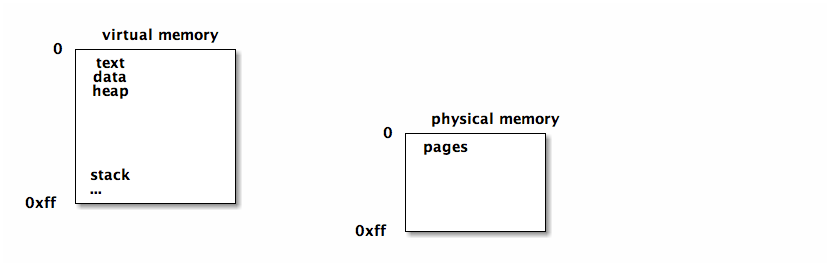
if a page of virtual memory is not in physical memory a page fault occurs and the page is loaded into physical memory
working set / footprint
of a process is the parts of it's address space currently in use. this is the pages of memory that need to be loaded in physical memory to avoid memory.
design goals
- efficiency
- often a tradeoff between time and space
- robustness
-
fulfills expectation of users
- security
- hardware interface
- expose features/capabilities of hardware
- user interface
- present features/capabilities to user
- portability
- target hardware
- economics
- development cost, user base
- scalability
- range of supported hardware/user sizes/numbers
- extensibility
- ability to support new components
papers
keep in mind the context
- users back then were developers
- cpu used to be bottleneck now it's memory
increasing gap between CPU speed and the ability of memory and bandwidth to keep up.
- bandwidth is proving the limit on the amount of memory which can be used efficiently
observations
hints
2009-09-01 Tue
Stephens Richie and Thompson developed unix and TCP/IP
-
Stephens
- part of the unix team
- wrote the unix bible
2009-09-03 Thu
- uni-programming
- only one process at a time, typically it would run to completion
- batch-programming
- still uni-programming but you maintain a queue of processes that are ready to run
- multi-programming
- allows multiple processes to run "simultaneously" on the machine using preemption, time slicing and by utilizing different hardware components in parallel
- time sharing
- multi-programming with multiple users creating processes. these days, tend to make the most sense for large batch processes, rather than interactive use
Mechanisms for multi-programming
- context switch
- switching processes on a CPU
- process table
- maintained by the OS, this contains an entry including a process control block for each process currently running on the system
- process control block
- contains the PID, the files the process is using, the program counter, register values, a pointer to the image
- image
- when you are about to run a process you load that process which creates an image of the process and bring it into memory. image+state=process. program -> image -> process
file systems
- file
- in general to the OS a file is just an uninterpreted raw ordered set of bytes, some specialized OSs do differentiate between file types for optimization.
- directory
- list of files, most OSs limit access to these files to system calls
mechanisms
- filename relates to an index # which points to the index table which relates the index # to an i-node
- when mounting a new disk the first couple of bites on the disk contain the information used by the OS to populate the index table
- generally corrupt disks are the results of damage to this meta data section on the front of the disk
links
- hard link
- the contents of the file is a pointer to the i-node of the file
- soft link
- the contents of the file is the name of the file to which it is pointing
deleting a file
- the actual data isn't "erased", rather the link counter in the i-node is decremented, and if there are no more links, then the blocks on which the file is written are added to the free list
- deleting a soft link doesn't change it's target's i-node
2009-09-08 Tue
- processes
- unit of work user gives to the OS
- thread
- finer unit of work inside the process
processes
schedulers
- batch queue
- outside the OS, waiting jobs
- short term scheduler
-
many different scheduling policies
- round robin
- priority
- shortest-first
scheduling
scheduling policy
- dispatcher
- implements the scheduler policy
- goals
-
- timing
-
- responsiveness
- time to first response
- waiting
- total time spent waiting
- turnaround
- time start to finish
- resource utilization
- users don't really care about this
policies
- fifo
- first in first out
- round robin
- move around giving everyone time slices
- shortest job first
- theoretical, not in real life
- priority
- not a complete policy, combined with fifo or round robin etc…
- multi-level queues
- semantics added to queues (i.e. system, interactive, batch, IO-bound, etc…)
- multi-level feedback queues
- jobs can change priority over time, based on things like increasing the priority of long-waiting jobs to avoid starvation
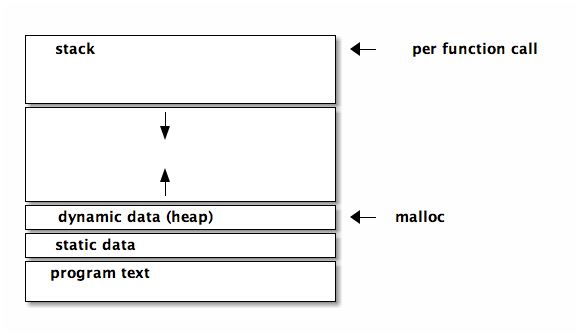
threads
multiple processes sharing an address space
each thread would have it's own
- UID
- stack
- registers
- defining handling signals like C-c, segmentation violations, etc…
everything else is shared (text, static data, dynamic data)
threading schema
- many-to-one (user-level threads)
-
don't really speed up execution,
but could help to modularize a program
- if one thread blocks for IO, all threads are blocked
- thread operations (creation, deletion) are performed in user-space which makes them faster than having to do them in kernel space
- one-to-one (kernel threads)
-
- real parallelism
- less portable
- takes longer to create a thread
- real parallel execution
- many-to-many (hybrid)
-
- static
- static mapping between user-threads and kernel-threads
- dynamic
- thread mappings can be changed
- pool
- you can establish a pool of kernel threads, then do all further thread operations in user-space (faster)
- limit
- you can limit the number of kernel threads to something reasonable (number of processors) reducing overhead on the OS and times jumping the user|kernel boundaries
- complicated
- this is the most complex of the threading schemas
- fixed
- most often you have a fixed number of kernel threads
inter process communication
through sharing or message passing. each of these could be implemented in terms of the other
in both cases
- synchronous == blocking - asynchronous == non-blocking
message passing
- µ-kernels can be though of as using message passing
- messages typically have to pass through kernels
- can cross machine boundaries
shared memory
- monolithic kernels can be thought of as using shared memories
- typically faster than message passing
- requires shared physical media
-
when two processes try to access a variable at the
same time
- i read
- you read
- i process and write
- you process and write
- we've both missed the other's changes
- atomic operations, locks, semaphores (binary, counting), etc…
2009-09-10 Thu
talking about µ-kernels.
address space == process
L4 kernel has hierarchical address space
- every process inherits address space from a parent, and the initial address space (sigma-0) maps directly to physical memory
-
which is like monolithic unix where everything descends from the
initprocess. - manages address spaces
paging vs. contiguous allocation
- contiguous allocation
- has a base and offset registers which are used to map the virtual addresses to the physical disk
- paging
-
pages of memory map randomly (not contiguous) on disk
- more complicated translation from virtual to physical addresses
- allows you to fill holes one disk (finer granularity because physical memory is eaten in page-size chunks rather than address-space chunks)
- allows portions of the address to be loaded individually as opposed to contiguous allocation where the entire address space must be loaded before any execution can take place
1st v.s. 2nd generation µ-kernels
- second tailored more to hardware
- second built from scratch (rather than back from monolithic kernels)
interrupts (µ-kernel is slower)
main reason µ-kernels are slower is because every interaction is translated through IPC which has to go through the table
- monolithic kernel
- hardware interrupts in a monolithic kernel are directly looked up in a register table
- µ-kernel
- one thread waiting for each potential interrupt source
top-half / bottom-half interrupts (in linux)
tradeoff between speed of handling interrupts, and need to do significant amount of processing in many cases
- top-half
-
responds quickly and does what needs to be done
immediately
- for example it will just record that the interrupt occurred
- has high priority and can interrupt other interrupt handlers
- setup
- bottom-half
-
does the actual bulk of the work
- has lower priority
- service
system call mechanisms
.soshared object- can be shared across multiple address spaces
.astatic shared code- statically linked (shared) at compile time
- trampolines
- jumps the code execution to somewhere else, then jumps back
scheduling
in L4Linux the normal linux scheduler is used much like a many-to-one thread scheduler. Maps all of the linux "user-threads" to a single kernel thread.
the L4 kernel is scheduled using hard priority round robin
L4 scheduling priority levels:
- top-half interrupt handler
- bottom-half interrupt handler
- kernel (which is the linux server)
- user
translation look-aside buffer (TLB)
Fast associative memory that helps in address translation
It maps a virtual address to a physical address, if you hit in the TLB, then you don't have to look up the page.
- tagged TLB
- like a TLB plus information as to which process the address belongs to
in a normal TLB you have to flush all entries in the TLB to clear old mappings, in a tagged TLB you don't need to flush the TLB on context switch. this saves time which quickly switching between processes and back.
dual space mistake
tried to facilitate speedy kernel <-> user IPC through shared memory
- space costs (doubling memory usage)
- synchronization costs (takes time)
co-location
allows multiple processes to all have access to kernel memory, like threads
2009-09-17 Thu
Project Ideas
-
System monitoring stuffs
- DynInst
- KernInst
- PIN
- PAPI (Performance API)
-
massively parallel stuffs
- map-reduce
- hadoop, w/PIG
- MRNet large scale group operations
- RPC
- XML-RPC
- task-farming (programming model, issue tasks to the farm and collect results, example SETI-at-home)
-
threads
- end-to-end threading model
- deadlock prevention
-
file systems
- encrypted
- process hijacking
- project HAIL
- FUSE (MAC-FUSE)
- Amazon Dynamo
exokernels
secure bindings
pain to write to
the spirit of the exokernel is that you would normally use abstractions exported by the library OS rather than always having to use your own
µ-kernel vs. exokernel vs. monolithic-kernel
-
Monolithic kernel
+------------------------+ | S1 S2 S3 | | | Monolithic kernel | S4 S5 | +------------------------+ ^ App -
µ-kernel
+------+ |App | +------+ | |-\ | App | +------+ -\ | | +-------------+ +-/----+ | | /- | | /- | u-kernel |-- +---/-----\---+ / -\ /- --\ / +---------+ +--/-----+ | S2 | |S1 | | | | | +---------+ +--------+ -
exokernel
+----+ +----+ +----+ |App | |App | |LOs | +----+ +----+ +----+ +-------------------+ | exokernel | +-------------------+ | Hardware | +-------------------+
downside (cooperation)
when each application has direct access to the hardware it becomes difficult for applications to cooperate (intelligently share resources), which is routinely done in standard kernels.
2009-09-22 Tue
monitors
(see ../cse451/notes/2007-10-17)
software construct which provides for mutual exclusion around a resource. maintains the invariant that when entering a monitor there is no-one else inside of the monitor.
- condition variables
-
allow communication between processes
avoiding spinning (
while(condition !true);)-
signal()alerts other processes -
wait()sleep (relinquish cpu) and wait to be signaled
-
- semaphore
-
semaphores are effectively equivalent to condition
variables
-
sem.p()waits on the semaphore -
sem.v()signals those waiting on the semaphore
-
Synchronization Problems
Mesa Monitors
Mesa
-
programs comprised of modules
-
clear API boundary between modules
- public interface
- private procedures
-
clear API boundary between modules
Mesa Monitors
-
monitor module
- entry procedures (publicly interface)
- internal procedures (private procedures)
- external procedures (procedures that require no locking)
Issues
-
when in a monitor (in function
foo), and you call a functionbarin another module then during the execution of that function you are not in the monitor (barhas no access to the structures of the monitor while as it is another module)-
if you don't release the lock when moving into
bar-
you have the risk that something in
bartries to grab the resource protected by the monitor /deadlock/ -
you have to
unwindand open locks if say there is a deep exception
-
you have the risk that something in
-
if you do release the monitor while calling
baryou need to-
ensure that you get the monitor back after executing
bar -
potentially do cleanup before/after executing
bar
-
ensure that you get the monitor back after executing
-
if you don't release the lock when moving into
- this is tradeoff between simplicity (per class) and efficiency (per object), best option really depends on the use case. monitor per class is sort of a strawman
-
it is possible for lower-priority processes to
run in front of higher-priority processes.
- p1 acquires l1
- p2 preempts p1
- p3 preempts p2
- p3 acquires l1 (but can't because p1 has the lock)
the problem is that p2 will run in front of p3, because p1 can't run and release the lock until p2 has run to completion
- priority inheritance
- associate a priority with a resource (lock) and the priority of that lock is set to the highest priority of those processes waiting for/on the lock. the priority of the process inside the lock is set to the lock's priority.
Difference between Mesa and Hoare
-
in Hoare you are guaranteed that immediately upon signaling of a
condition variable the waiting process will receive control, however
in Mesa monitors the signal is more of a hint and you are not
guaranteed to receive control when a signal is sent.
-
Hoare
if(!cond){condition_v.wait()} -
Mesa (must re-check after condition becomes true)
while(!cond){timed_wait()}
-
Hoare
-
Mesa
- timeout
- abort
- broadcast vs. signal
- naked notify
-
allows hardware interrupt to signal a condition
variable without first acquiring the monitor lock. this is
more efficient than forcing a device driver to wait for a lock
to be released before accessing a monitor.
-
this could lead to a problem where a device signals that a
resource is free, but the notification is missed by a process
which is just switching from
!condtowait() - note that this only allows the hardware interrupt to signal the condition variable, not to actually touch the resource
-
this could lead to a problem where a device signals that a
resource is free, but the notification is missed by a process
which is just switching from
2009-09-24 Thu
scheduler activations
wherever their system does well they present the numbers in a table. when their system doesn't fare so well they embed the numbers in the prose.
- virtual processors to real processors
- how do virtual processors map to real processors
- SMMP
- shared memory multi-processors, many CPUs which all have access to a single big block of shared memory
- normal user-level threads
-
may not really be that much faster than
kernel level threads (at least not to the point that this paper
claims)
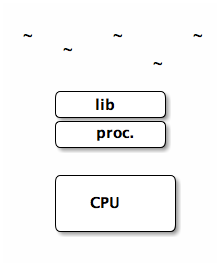
- these user-level threads
-
in this paper when they say user-level
threads they mean the following model
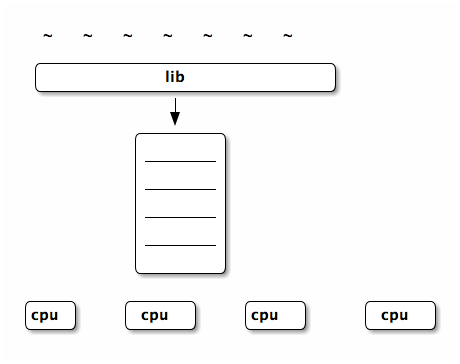
- kernel scheduling
- priority levels and equal access for each priority level
- lifo
- when there are not enough processors to run all threads, then they follow a lifo policy to take advantage of cache locality (if I was running recently then my cache is still around)
- critical section
-
need to be careful not to preempt a thread in a
critical section (or at least let it get back quickly)
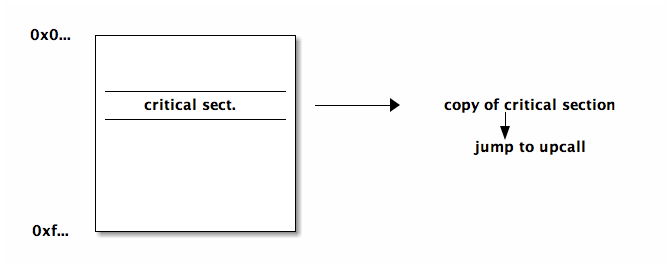
when a guy in a critical section is preempted and other people are waiting for his lock (and they've pushed him down the lifo queue) then you could deadlock (as he can't get up the queue until they finish and they can't finish until he runs)
- solution
- make a copy of each critical section which ends in a jump to an upcall. when the kernel preempts a process the kernel checks if the code is in a critical section, and if so, it jumps to the copy which is guaranteed to jump to an upcall when the section completes
- spin lock
- burns CPU, but keeps a process on the ready list, good for short wait, or when you have processor to burn
- upcalls
-
used for the kernel to talk to the user process
- preemption
- adding procs
- blocking
- unblocking
- downcalls
-
when the user-space communicates to the kernel
- more procs
- less procs
2009-09-29 Tue
lottery scheduling
a proportional-share-scheduling system where each entry (waiting consumer/process) gets some number of tickets, and whenever a resource is to be consumed a lottery is held and the winner's ticket is taken and the winner is placed in control of the resource.
specifics
- actually help many lotteries at once forming a queue (rather than a lottery every time quanta)
- processes can give their tickets to other processes (i.e. client server model, client could give tickets to server)
- given to processes that release the CPU before their time quantum has expired
- more uniform stat distribution with more samples -> smaller quantum leads to more samples
-
tickets can be used for any resource
- memory management
- reverse lottery, when a page needs to be evicted from memory a lottery is held to select page to remove
resource containers
aimed at implementing a web server
relevant metrics for web server
-
client metrics
- response time
- throughput
-
server metrics
- number simultaneous clients
- quality of service, might want different levels for different clients
resource containers allow the application to specify resource containers and tell the kernel how to assign resources to the resource container.
mechanism of resource containers
- connection comes in and is wrapped in a resource container
- thread handling that connection is bound to the resource container
- additional resources (i.e. file descriptor) are bound to the resource container
this can be useful for handling malicious requests (i.e. if they're tagged as malicious on the way in they can be given little/no resources)
memory management
handling the speed/capacity tradeoffs of memory maintaining
- performance
- protection
- correctness
/\
/ \ |
speed ^ / \ capacity v
| / reg. \
/--------\
/ \
/ cache \
/--------------\
/ \
/ main memory \
/--------------------\
/ \
/ local disk \
/--------------------------\
/ \
/ cloud, remote disk, tape \
----------------------------------
relocation
addressing schemas (w/static relocation)
- source code
- symbolic representation of memory addresses
- compiled code
- relative refs (e.g. module x + offset)
- loaded code
- absolute addresses
so to change where the code is located in memory you will generally need to reload the code. dynamically relocatable code has it's absolute addresses resolved at runtime rather than at load time, so the code can be moved without reloading the code.
allocation
- contiguous allocation
-
simple (base, limit, attr). makes context
switches very simple (the kernel only need to change the base and
limit registers)
- external fragmentation
- may not have enough contiguous free space
- sharing
- can't share w/o sharing entire address space (no portions)
- setting attributes
- same as above, can't identify parts of the space
- segmentation allocations
-
divide address space into segments of
arbitrary size. segment number -> (base, limit, attr)
- external fragmentation
- because with variable length sizes there could be many free spaces which aren't big enough to be used
- paging
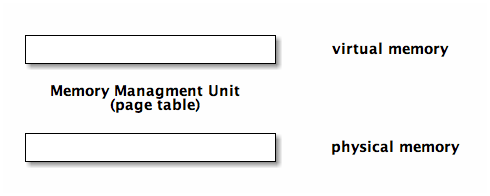
- (most popular) fixed size segmentation. this ensures that there is no external fragmentation (if there is any space available then it is page sized and can be used). this is still vulnerable to internal fragmentation
page table
2009-10-01 Thu
2009-10-06 Tue
disco (implementation & performance)
OS modifications
- drivers for DISCO specific "hardware"
- changes to keep OS from trying to access a small chunk of unmapped memory
- (small) allows the guest OS to request a 0'd page (so the guest OS doesn't have to re-0 a page)
- (disco) interprets the guest OS going into low power mode as the OS yielding the processor
virtual memory
Multics
- since segments are organized/structured as files they actually didn't have a file system. referencing a segment through it's symbolic name is like referencing a file
-
seg.tag | address | opcode | external | addressing-mode- seg. tag
- points to the base register of the owning base register
- external
- whether to use the segment tag (if external) or your own base register
-
address points to another address. happens
when you have multiple levels of paging hierarchy.
- indirect address points to 2 36-bit words, the new segment number and the new word number
-
reference to external program
- symbolic name -> module name
- symbolic address -> function name or variable name
- are added to each process to hold the lookup information for external segments. after an initial reference the number of the link in the linking segment is used for future references.
VAX
- VMS addressing
-
2-bit seg. | 21-bit page number | 9-bit offset- segments
-
system space, program region, control region
- program region
- user data for the program
- control region
- kernel data for the program
- TLB
- the TLB is split in two (system/process), less has to be flushed on context switch
2009-10-08 Thu
VM pros and cons
-
pros
- larger address space
- convenience in segmentation and paging
- code portability
-
cons
- (time overhead) increased effective memory latency
- (space overhead) maintaining mappings, page tables
- increased complexity
2009-10-20 Tue
disks and file systems (see related 481 slides on Dorian's homepage)
disks
- disks
- stack of platter of concentric circles (or tracks) of sectors along with a movable arm (in all modern systems) and there is one arm/head per platter. each platter (aside from top and bottom) has data on both sides.
file system
semantics on top of disks
abstractions
- files
- directories
handles
- permissions
- mapping abstractions to disk
- enforcing resource quotas
directory
-
just a special file which consists of a list of entries
- directory entry contains: filename, id, inode-#
-
certain operations (
cd,ls) can only take place on directory files -
organizations (in increasing complexity)
- 1-level directory
- 2-level usernames/files
- trees (graph with no cycles)
-
acyclic graphs (sharing: multiple links to the same content)
- soft/symbolic link
- the file just maps to the name of another file (allows dangling pointers)
- hard link
- actually copies the inode-#, an inode (and the file) is removed when there are no more hard links pointing to the inode. this information is tracked in the inode
- general graphs
filesystem on disk:
- boot control block
-
volume control block
- # of blocks
- # free blocks (list)
-
directory structure
- starts @ root disk
- filenames, inode-#s
-
file table
- maps inode-#s to inodes
when a device is mounted the OS loads the filesystem structures into memory
filesystem in memory:
- mount table
- cache directory structure
-
open file table (another cache)
- variations: system wide or per process (know the pros and cons of each of these options)
- caching (pages/contents of the files)
2009-10-22 Thu
going through the midterm
Grade Distribution
| mean | med | max | max possible | |
|---|---|---|---|---|
| p1 | 23 | 25 | 30 | 30 |
| p2 | 11 | 12 | 14 | 15 |
| p3 | 19 | 20 | 25 | 25 |
| p4 | 8.7 | 10 | 15 | 15 |
| total | 61 | 61 | 84 | 85 |
Review of problems (in general on the exam less is more)
-
-
-
exokernel, library OSs are linked into the application space of the
application, so the
getpidcall is just a function call in the user-space which would not have to cross the user/kernel boundary, so this would be faster than the monolithic kernel -
-
protection, multiplexing, IPC
-
-
exokernel, library OSs are linked into the application space of the
application, so the
-
3) 1)
-
-
-
it is much more complicated to move a process than to move a
block of data. if you have many readers/writers of a block of
data it may make more sense to move the users to the data
rather than moving/replicating the data.
-
- in message passing structured IPC using copy-on-write can allow pointers to be passed from process->kernel->process rather than the actual block of data
-
it is much more complicated to move a process than to move a
block of data. if you have many readers/writers of a block of
data it may make more sense to move the users to the data
rather than moving/replicating the data.
-
2009-10-27 Tue
will discuss LFS and RAID on Thursdays
- LFS
- wanted to improve performance and ended up improving filesystem reliability
- RAID
- vise-versa
Network Files System (NFS)
remote file access
-
pros
- larger file servers (capacity)
- sharing
- robustness / redundancy
-
cons
- speed (latency)
- availability
- consistency
- complexity
-
NFS specific goals
- 80% speed of local disk
-
simple crash recovery
-
can repeat operations until success (idempotent). many
operations are not naturally idempotent, for example the read
operations
read(f, out, nbytes)would normally increment a counter in the file, in nfs this counter must be tracked on the client side and passed as a parameter to the server
-
can repeat operations until success (idempotent). many
operations are not naturally idempotent, for example the read
operations
- no state on the server
- transparent access
- preserve Unix semantics
-
Deployment Issues
- sharing the root file system
-
scalability/performance sharing heavy use files (e.g. binaries
required on startup)
- made these files local to each individual node
-
/tmpfiles (use the process ID, which wouldn't be unique across different nodes) -
/deventries of this directory have local semantics which make no sense to access on a remote system - authentication across machines (need a global system of user IDs, "Yellow Pages")
- concurrency: local locks but no global locks, so two users on different nodes could have their writes to a file interleaved.
-
performance: (solution is always caching)
-
calls which occur often, but transfer small bits of data,
(e.g.
getattrwhich is called byls, and pretty much every file access, this was initially 90% of the transactions) – so, they just cached attributes, this cache is invalidated every three seconds for files and thirty seconds for directories -
used
UDP(Unreliable Data Transport), so if a packet in a RPC is lost they'd just redo the RPC -
really big packets
- read-ahead to try to get blocks before their needed – this doesn't help for executables with random access patterns
-
calls which occur often, but transfer small bits of data,
(e.g.
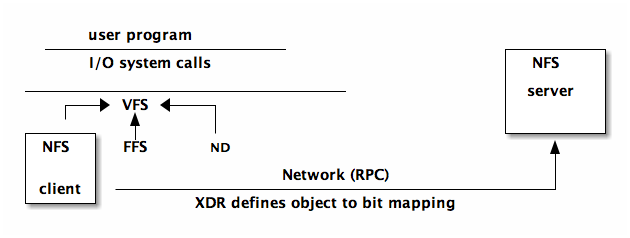
- VFS (virtual file system) abstraction on top of the specific file system used. allows file systems to be plugged in sort of like device drivers
- XDR is used as a canonical data representation ensuring that when the client and server share objects (ints, arrays, etc…) they cache their objects out into bits in the same way (endianness, float representations, etc…)
2009-10-29 Thu
(if we are ever really interested in a paper we could lead that lecture)
disk failures
updates, 3 parts – related to disk failure
- (D) data blocks
- (F) free blocks
- (M) meta-data blocks
disk failure part way through a write could lead to incoherence in the three above. most FS will perform the above in such a way the any inconsistency is a "functional" inconsistency – while space may be wasted everything will still "work".
some crash cases
- (D) -> crash
- no real problem, just wasted time writing to a block that's still on the free list
- (D) -> (F) -> crash
- leaked a data block that will not be recovered
- (F) -> (M) -> crash
- functional problem, file points to whatever was previously on disk (garbage or someone else's old data)
fsck checks that
- all blocks not on free list are in use – referenced by an inode
- all blocks referenced by an inode are not in the free list
journal/log-structured differences
- journal – transactions in progress which can be used to recover from crash/failure
- log structured FS – actually uses the log as the only structure on disk
RAID / LFS
writes are buffered in main memory until there is a segments worth of data to write to disk. This allows the entire segment to be written w/o any seeks taking advantage of the disk's full bandwidth.
in RAID there is a slowdown factor of N when writing to N disks.
in LFS the checkpoints become the journal
RAID levels (5 and 1 are the only common levels)
- striping across a single disk
- straight mirrored disks, faster reads as you can read from both disks and whichever returns first wins (best case seek), for a write you have to wait for the write to complete on both disks (worst case seek)
- Hamming code for ECC
- Single check disk per group
- Independent read writes
- No single check disk (large performance increase over RAID level 4)
note know the basic read/write operations for each level and be able to discuss the performance implications
2009-11-03 Tue
LFS and RAID
- LFS
- main point is the caching setup. user <-> cache <-> disk
- RAID
-
don't need to know the names of the specific levels, but
should be able to derive the mechanisms for reading/writing, as
well as the implications speed/reliability for these mechanisms.
RAID can be implemented in hardware or software. Be able to
extend these concepts (e.g. RAID 7 is )
- 0
- block-level striping
- 1
-
simple mirrored disks
- read: could use either disk (faster), for a multi-block read each disk could serve up different blocks
- write: will necessarily use both disks
- 5
-
block-level striping and distributed parity – parity is
spread across all disks
- read: will either only touch the specific disk which the block lives on, or will read all disks (including parity) and will reconstruct the data
- write: must touch all disks, writes to the disk on which the data will live and to the parity disk and reads from the other disks to calculate the parity
blocks and sectors
- block
- software construct, typically will be equal in size to either a single sector or multiple sectors
- sector
- the actual size sections of the physical disk
CODA
- call backs are used in asynchronous operations, they alleviate the need for active probing. allows the server to alert the client when a change occurs – used in CODA for cache coherence
2009-11-05 Thu
general consistency
by and large message passing has beat out shared memory when it comes to distributed computing. MPI is the de-facto distributed memory standard openMP is a new message passing alternative.
typically there is no global clock
- strong consistency
- (called sequential consistency in Munin paper) any write is immediately visible to subsequent reads
- causal ordering
- uses communication between processes to determine a global partial ordering
- weak consistency
- this is not really ever used. makes no guarantees that writes will be visible to future reads
- eventual consistency
- write will eventually be seen
- release consistency
- requires data to be visible only at certain synchronization points (i.e. at release or barrier)
Munin
Munin – shared program variables are annotated with their access pattern which is used by the OS
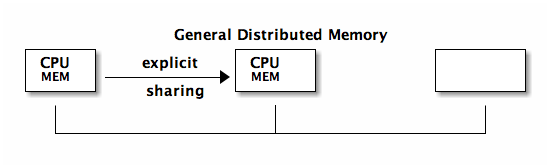
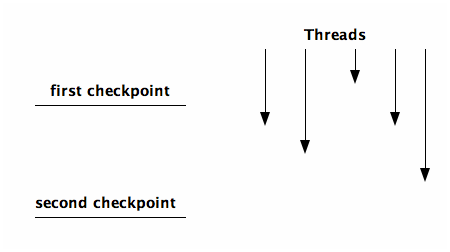
- barrier
- designate a point where you will wait at that point until every other thread gets to that point
- split-phase barrier
-
two checkpoints, everyone can pass the first
checkpoint arbitrarily, but no-one passes the second checkpoint
until everyone has passed the first
Munin Annotations and Protocol Parameters
| annotations | I | R | D | FO | M | S | FI | W |
|---|---|---|---|---|---|---|---|---|
| read-only | N | Y | N | |||||
| migratory | Y | N | N | N | N | Y | ||
| write-shared | N | Y | Y | N | Y | N | N | Y |
| producer-consumer | N | Y | Y | N | N | Y | N | Y |
| reduction | N | Y | N | Y | N | N | Y | |
| result | N | Y | Y | Y | Y | Y | Y | |
| conventional | Y | Y | N | N | N | N | Y |
Meanings of Parameters
| I | invalidate or update |
| R | replicas allowed? |
| D | delay vs. immediate |
| FO | fixed owner? |
| M | multiple writers allowed? |
| S | stable sharing pattern? |
| FI | flush changes to owner |
| W | writable? |
Non-functional performance enhancing objects
- ability to map an object to a lock
- ability to explicitly flush changes to an object
Implementation
- maintained a hash table mapping object addresses to their attributes
- copyset was a list of where (which processors) an object currently exists
- delayed update queue (DUQ) to hold updates which will need to be propagated, generally held until barrier and then sent to everyone in it's copyset
question: why only use twins when there are multiple writers?
2009-11-10 Tue
Munin implementation
- DHT or Distributed Object Directory
-
delayed update queue
- page twins: two copies of a page used to find out what the differences are between old/new versions of the page
- distributed locks were effectively a queue, person at the front owns the lock and everyone else is further down the line.
page faults used to track updates
- write protect pages that process would normally be able to write to
- when page faults allow write to go through but make a note and maybe update remote copies of the page
Quicksilver
- transaction
-
collection of operations into a single atomic unit of
consistency and recovery. techniques include…
- locks
- mutexes
- semaphores
- monitors
- h/w instructions
- interruptible disabling
- commit protocols
-
some things to be considered as goals
- atomicity
- recovery semantics
-
minimize overhead
- blocking/sync
- logging overhead
- communication
- two phase commit
-
coordinator and subordinates
transaction_begin 1 2 3 ... transaction_end
-
the coordinator
- initiates the transaction
-
preparemessage is sent to all subordinates - subordinates act and respond
-
send
commit
-
the subordinate
-
upon receipt of
preparemessage the subordinates reply with eitheryesorno -
no-> veto -
or go to
preparedstate and update logs and respondyes
-
upon receipt of
-
the coordinator
2009-11-12 Thu
Quicksilver
locks used to make a monolithic unit out of a series of operations
- short lock
- would only be held for a single operation inside of a transaction
- long lock
-
could be held for an entire transaction
short locks long locks read write - degree 0 consistency
-
short write lock and no read lock
- cascading abort
- dirty reads
- non-repeatable reads
- degree 1 consistency
-
long write lock and no read lock
- dirty reads
- non-repeatable reads
- degree 2 consistency
-
long write lock, and short read lock
- non-repeatable reads
- degree 3 consistency
- long write lock, and long read lock
locks in the context of their DFS (Distributed File System)
-
directories
- locks for renaming, creating, deleting
- write lock for dir.entries
- no read locks
-
files
- short read locks and long write locks
highlights (distinguishing features)
distributed OS using transactions for data consistency
wrapped applications in trivial transactions, so bad quit would remove all previous changes
in order to share a transaction with another process you would need to fork that process
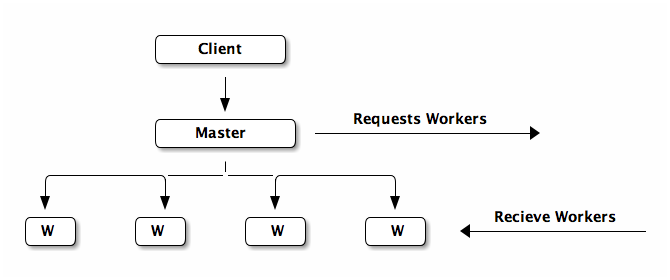
Cluster Based Scalable Network Services
advantages
- small unit of fault -> robust
- scalable
- cost effective
BASE
- Basically Available
- Soft state
- Eventual consistency
Condore is another system that finds idle machines and sends them work when work accrues
implementation
components of the system
-
front end
- http server
- thread pool
-
workers
- to provide services
- to hold the results of computation
- report failed services to the manager
-
manager
- calculates load and sends requests to the front-end
- receives failure reports from workers
failure peers vs. failure pairs
- failure peers
- manager watches front-end and restarts if it crashes and vice versa
- failure pairs
- more generally called hot backups where each component has a backup which can take over if one fails
2009-12-01 Tue
cover CFS and do Map-Reduce on Thursday, presentations starting next week
final
- lets try to do a final-review outside of class
- final will sprinkle questions over the first half, but will focus on the second half
project
- paper is due at the end of next week
- 10-12 minutes per group – 8-10 slides
CFS
- lookup
- (finger table and successor list) the successor list was slow because on average you would have to touch half the servers in the system, so the finger table was added to store IDs of far away people for quick jumps to distant portions of the circle.
- caching & timeout
2009-12-03 Thu
map reduce
-
stream programming collection of filters which the data passes
through
+---+ | F | +---+ /- -\ / -\ /- -\ +-+ +---+ |F| | F | +-+ +---+ -\ /-- -\ /- +---+ | F | /+---+\ /-- ---\ +-+ +---+ |F| | F | +-+\ /+---+ \ / \ / \ / +---+ | F | +---+
- consistency
- can handle failures in workers (just aborts if master happens to fail) by repeating the computation for failed workers. this mains that the worker tasks can happen multiple times – so they must be idempotent (i.e. side effect free). also the computation would need to be deterministic for re-doing of failed nodes to have no effect.
- backup tasks
- only as fast as your slowest worker – so as workers finish the unfinished tasks are duplicated to idle workers in the hopes that someone new will finish the task earlier
- combiner function
- can be run on the local map worker to compact the data before it is sent of to be reduced
- skipping bad records
- when some records continually cause workers to fail then they will be skipped
- local execution
- ideally workers will be selected which are close to the data which they will be analyzing
reading notes
Map / Reduce
Amoeba vs. Sprite
both truly distributed operating systems in contrast to most of today's large distributed system which has node-local OSs with a global managing agent.
Network Services
QuickSilver
Munin DSM
CODA
RAID
NFS network file system
log file system
fast file system
Old FS: (order on disk)
- superblock
- inode blocks: direct (first 8 blocks) v.s. indirect blocks
- data blocks: size (initially 512 then up to 1024)
issues with this setup
- inodes not located near the data, so many non-contiguous jumps
- issues with fragmentation
- didn't take advantage of the structure of the disk (too much random access of the file)
New FS:
- collocated inode and file data (in the same cylinder group)
- replicate the superblock information across all cylinder groups (reliability)
-
variable block sizes (4k block size has average 2k internal fragmentation)
- split each block into anywhere from 1-8 fragments (powers of two) and managed free space on a fragment (rather than block basis). this can incur bookkeeping and overhead problems (as a file increases in size it may need to be continually copied between fragments and blocks).
- exploit h/w characteristics by trying to adjusting notion of "contiguous" based on the speed with which the disk can move between segments
- collocate directories and files
VM in Multics
goals
- provide the user with a large virtual memory hiding moving of data between levels, and any machine-dependent stuffs
- allow procedures to be called by name w/o any need to plan for the storage of the called procedure
- permit sharing of procedures and data among users subject only to permission restraints (vital to efficient operation in a multiplexed system)
process, address space
processes and address space stand in a one-to-one correspondence
address space is composed of variable length segments, each segment is either data or procedure which affects it's access permissions.
segments are addressed using a directory structure similar to files.
addressing
- generalized address
- consists of a segment number and a word number
- address formation
-
based on values of processor registers,
different for process/data segments
- process
- segment number in procedure based register + the program counter
- data
- the segment tag of instruction selects a base register if the external flag is on. otherwise the segment number is taken from the base register
- indirect addressing
- in this case the generalized address is used to fetch two 36-bit words, these are combined to form another generalized address. can be nested
- descriptor segment
- generalized-address -> main-memory is done using a two-step hardware lookup
- paging
- of segments allows non-contiguous segments of main memory to be referenced as logically contiguous generalized addresses
intersegment linking and addressing
shared access and building upon others addresses are both important goals of multiplexed machines
requirements
- pure procedure segments execution can't change their content
- symbolic procedure calls without making prior arrangement for the procedure's use
- segments of procedure invariant to recompilation of other segments
implementation
- making a segment known
- when the segment is called by symbolic name it is added to the caller's description segment and can later be referenced by number
- linkage data
- a processes code must be invariant to compilation, so the process will always use a segments name/path to address it. after the segment is known, then it's number can be used. a linkage segment will hold the information on name/path -> number transformations so that the numbers can be used for known segments w/o changing the contents of the process
VM in Vax
process & virtual address space
page number and offset within the page
address space divided into spaces (not segments)
- system space
- high-address half is system space and is shared across all processes. This contains OS stuff, executive code and protected data.
- process space
-
low-address half (for the process)
- program region (P0)
- low-address half of process space. contains the user's executable program. first page is reserved to cause errors on 0-address references
- control region (P1)
- high-address half of process space. this region is used to hold process-specific data
each space/region has it's own page table
- system space page table
- in hardware, not swapped on context switch
- process tables
- in the system-space, are swapped on context switch
memory management
paging issues
- effect of heavy pagers on other processes
- high cost of startup/restart (by faulting it's way into main memory)
- increased disk workload of paging
- processor time searching page lists
pager and swapper
- pager
- OS procedure resulting from page fault
- swapper
- separate process which moves pages into/out-of memory
dealing with the above issues
- the pager deals with this issue by evicting pages from the process which is requesting the new page, so one process won't push out everyone else's pages. also a limit is placed on the number of pages a process can have in memory.
- the above helps with this as well
- the VAX clusters the reading and writing of pages to relieve I/O burden on the disk
- by not having a reference bit (used to mark recently used pages) the VAX system takes load (scanning page tables and setting these bits) off of the processor
when pages are removed they are placed on the free page list or the modified page list depending on their modified bit and whether they need be written to memory. these lists serve as physical caches for recently removed pages (it is quick to move a page from one of these lists back to the working memory).
by caching the modified pages in the modified page list the following for speedups are gained.
- caches pages for quick return to the process
- clustered writes (~100 pages on the development system)
- arranged on paging file so clustering read is possible
- many page writes are avoided entirely
additional structures
- demand zero
- when processes require new pages they are created and filled with zeros on demand
- copy on reference
- when multiple processes using a page
program control of memory
for real-time programs that need explicit memory control
- expand it's P0 or P1
- increase it's resident set size
- lock (or unlock) pages in it's resident set
- create/map sections into it's address space
- record it's page-fault activity
Scheduler activations
introduction
user threads vs. kernel threads
- user threads
-
- requires no kernel intervention
- fast (on order of procedure call)
- flexible
- each thread runs on a "virtual processor" which still has to be multiplexed onto a real processor and interleaved with system calls, and kernel stuff leading to a performance hit
- sometimes exhibit incorrect performance when involve I/O
- kernel threads
-
- directly maps each application thread to a physical processor
- heavy weight
- not a restricted (RE: side effects, I/O)
the goal of this paper is to combine user/kernel threads
- common case (no kernel required) perform as user threads
- acts as kernel threads when needs to talk to kernel
- easily customizable
- difficulty is that relevant information is scattered between kernel space and user address space
the approach described in this paper is to give each user-level thread system with it's own virtualized machine which can have any number of processors.
problems w/user threads over kernel threads
- kernel threads must implement anything that any reasonable user-level thread system may need (too much overhead)
- when a user-level thread blocks (for I/O, fault, etc…) it's kernel thread also blocks
- if we create more kernel threads then there are processors then the OS must make scheduling decisions without any information about the priority / current-task / importance of the related user-level threads
design (scheduler activations)
each user-level thread system gets it own virtual multiprocessor
- kernel gives processors to user thread systems
- user thread system has complete control over use of it's virtual multiprocessor
- user thread system can tell kernel when it needs more threads
- user thread system only talks to kernel when it needs to
- looks to the application programmer like they are using kernel threads
-
communication from the kernel to the
user-level thread system which may cause it to reconsider it's
scheduling decisions.
-
roles
- serves as the vessel or context of the user-level thread
- notifies user-level thread of kernel event
- stores user-level thread when it's blocked (e.g. for I/O)
-
when a thread is stopped
- the kernel stuffs it into it's activation
- creates a new activation to tell the thread system that the thread has been stopped
- the thread system removes the thread, and tells the kernel the activation can be re-used
- the kernel does another upcall giving the newly released scheduler activation (processor) to the thread system to run a new thread on
- there are all ways as many activations assigned to an address space as there are actual processors
- in the same manner processors are moved from one address space (thread system) to another
-
roles
-
how user-level thread systems keep the kernel
informed about their amount of parallelism
- inform kernel when more threads than processors
- inform kernel when more processors than threads
-
when a thread is interrupted while in a
critical section
- the kernel makes an upcall informing the address space that the threads processor is ready
- this upcall is intercepted and given to the thread until it is out of it's critical section
- the thread is then put back on the ready queue and the address space is free to respond to the new processor however it sees fit
implementation
implemented by tweaking
- Topaz
- the native kernel threads for the firefly machine
- FastThreads
- a user-level thread package
performance
- same order of magnitude as plain user-threads
-
upcall performance is slow, much slower than normal kernel thread
operations
- written on top of existing kernel thread library (not from scratch)
- written in higher level language (not carefully tuned assembly)
-
N-body problem
-
speedup with more processors
- some increase over fast-threads
- significant increase over kernel threads
- more robust than fast-threads to lower amounts of memory
-
speedup with more processors
related ideas
psyche and symunix are both NUMA OSs which provide virtual processors similar to activation contexts.
differences
- both psyche and sumunix provide for shared address space between kernel and thread systems
- neither provides the exact functionality of kernel threads (for I/O etc…)
- neither provides efficient system for user-level thread system to notify kernel when it's hungry
summary
combine the performance of user-level threads with the functionality of kernel-level threads. this is done by supplying each user-level threading system with a virtual multiprocessor in which the application knows exactly how many processors it has at any one time (and each processor maps to an actual physical processor)
- processor allocation (between applications) is done by the kernel
- thread scheduling is done by address space
-
kernel notifies address space of events affecting it
- new processor
- less processor
- preempted thread
- address space notifies the kernel if it needs more/less processors
Monitors (2)
Monitors: An OS structuring concept
-
monitors are procedures or functions called by software wishing to
acquire a resources along with local administrative data
monitorname: monitor begin.. declarations of data local to the monitor; procedure procname (... formal parameters...) ; begin... procedure body... end; ... declarations of other procedures local to the monitor; ... initialization of local data of the monitor... end;
-
a procedure will have to
waitwhen the monitor is in use - when the program is waiting for the monitor, it needs to be sure that after the monitor is released, the very next procedure to execute will belong to itself
-
there are multiple reasons that a program will need to
wait, so the program will have to set aconditionvariable to indicate that it is waiting for the monitor
example of a monitor (resource:monitor) with condition variable nonbusy
single resource:monitor begin busy: Boolean; nonbusy : condition; procedure acquire; begin if busy then nonbusy.wait; busy : = true end; procedure release; begin busy := false; nonbusy.signal end; busy : = false; comment initial value; end single resource
the above example simulates a boolean semaphore with aquire and
release procedures.
interpretation
a process inside a monitor may need to signal another process. the
signaler must wait for the signaled to complete and to allow it to
proceed, it can increment an urgentcounter to indicate that it had
control of the monitor and should get it back.
then whenever the monitor is released, the urgentcounter should be
decremented and the longest waiting process on the counter restarted.
similarly we need to be able to allow process in monitors to wait as
well as signal which could be implemented similarly (with a
waitcounter)
given the above the monitor can be explicitly passed form one process to another, and only released when there are no more processes in the explicit passing of control
bounded buffer example
two processes running in parallel share a bounded buffer, one is the consumer (eating form the beginning) and one the producer (appending to the end).
the following implements this setup
bounded buffer:monitor begin buffer:array 0..N - 1 of portion; lastpointer:0..N - 1; count:0...N; nonempty,nonfull:condition; procedure append(x:portion); begin if count = N then nonfull.wait; note 0 <= count < N; buffer[lastpointer] := x; lastpointer := lastpointer + 1; count := count + 1; nonempty.signal end append; procedure remove(result x :portion); begin if count == 0 then nonempty.wait; note 0 < count <= N; x := buffer[lastpointer - count]; nonfull.signal end remove; count := 0; lastpointer := 0; end bounded buffer;
scheduled waits
sometimes rather than just selecting the longest waiting process from a variable we would prefer to allow processes to have some priority
real world examples
- buffer allocation
- disk head scheduling elevator algorithm
- readers and writers (only writers need exclusive access)
- to ensure writers can access elements, no readers can start while a writer is waiting
- to ensure readers get access, all readers queued during a write are allowed to read before the next write operation begins
-
variables
-
startread -
endread -
startwrite -
endwrite - number of waiting readers
- is someone writing
-
conclusion
monitors can be an appropriate structure for an OS with parallel users
Experience with Processes and Monitors in Mesa
Lampson and his team seem to make everything harder than it should be
issues
- programming structure
- must fit monitors into Mesa's module based organization
- creating processes
- need to be able to dynamically create processes after compile time (adds complications)
- creating monitors
- need to be able to dynamically create monitors after compile time (adds complications)
waitin nested monitor call- is confusing
- exceptions
-
make Mesa's
unwindfunctionality work well with monitors - scheduling
- moving from recommendations to implementation proved difficult
- input/output
- again moving from theory to practice can be hairy
description
(see mesa-monitors)
implementation
equal division between
- runtime
- implements the heavier rarely used stuff like process creation deletion
- compiler
- implements the various syntactic constructs and translated into built-in support procedures
- hardware
- directly implements the more heavily used stuff like scheduling and entry/exit
performance
| Construct | Time (ticks) |
|---|---|
| simple instruction | 1 |
| call + return | 30 |
| monitor call + return | 50 |
| process switch | 60 |
| WAIT | 15 |
| NOTIFY, no one waiting | 4 |
| NOTIFY, process waiting | 9 |
| FORK+JOIN | 1,100 |
conclusion
integration of monitors into Mesa was harder than anticipated given the amount of literature on monitors and the high level of Mesa, however, much work was done to implement monitors in such a way that they can be used as the sole concurrency construct for an entire OS/language.
questions
- wouldn't it also be a problem if I'm in my protected block, and hardware barges in and takes over the resource (breaks the monitor invariant)
Virtualization
Commodity Operating Systems on Scalable Multiprocessors
comodity-os-on-multiprocessors.pdf
again cites the size and complexity of modern operating systems as limiting factor, this time in effectively utilizing massively multiprocessor machines.
rather than customize the OS this paper inserts a small virtual machine monitor between the OS and the hardware.
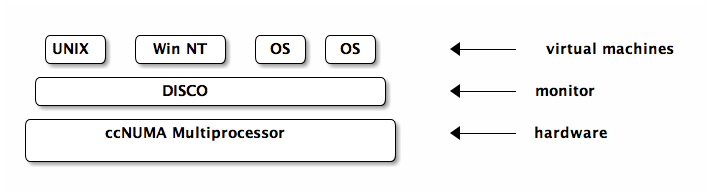
Demonstrated on the Stanford FLASH shared memory multiprocessor, with an experiments cache coherent non-uniform memory architecture or ccNUMA setup.
problem
hardware development moves very quickly, yet people like to bring all of their existing software (which is OS dependent) to this new hardware.
there is a need for quickly porting existing OSs to new hardware as this is the limiting factor in adoption of new hardware setups
virtual machine monitors
the virtual machine monitors serves as a thin layer between the hardware and existing comodity OSs (like windows NT or *NIX), exporting to each OS a set of virtualized resources which it is able to manage.
while the machine can communicate through standard external interfaces (NFS, TCP/IP), the monitor is able to efficiently assign resources across machines (i.e. one machine may get more memory if needed, etc…)
with small changes the OSs can explicitly take advantage of the shared memory between virtual systems (e.g. a database could put it's buffer cache in shared memory supporting multiple query servers)
the VM takes many burdens off of the OS
- only the VM need scale to the size of the hardware
- the VM can isolate separate OSs protecting from faults
- NUMA memory management
- in general handling hardware quirks
- VM issues
- overhead
-
-
additional
- exception processing
- instruction execution
- memory requirements
- large structure duplicated for each OS (file system buffers)
-
additional
- resource management
- the VM does not have high level information about the processing taking place, so it can't distinguish processing which is just the OSs busy loop from important calculations.
- communication
-
looks like different OSs on the same hardware
rather than each OS on it's own hardware, so
- same file can't be open in two different VMs
- same user can't start multiple VMs
DISCO (a virtual machine monitor)
DISCO is designed for the FLASH multiprocessor which consists of a collection of nodes arrayed on a high speed interconnect. each node contains a CPU, memory, and IO devices
Disco Interface
- processors
- exports a processor of the same type as those used by FLASH. OSs tuned to use disco can directly access some common processor functionality using special load/store instructions.
- physical memory
- exports continuous physical memory starting at 0, and handles all the NUMA stuff behind the scenes
- I/O devices
-
provides each OS with the illusion of their own I/O
devices. this means disco must intercept all I/O communication.
again provides special instructions for disco-aware OSs to bypass
this in special cases
- DISCO provides a virtual subnetwork which the machines can use to communicate amongst themselves
DISCO implementation
general
- as a multi-threaded shared memory program
- the small code portion of DISCO is duplicated across processors so page-misses are all local
- avoids linked-lists and other structures which perform poorly with caching
virtual CPU
- for speed DISCO direct executes most instructions and only tries to intercept dangerous instructions (like TLB modifications)
- runs in supervisor mode which is between kernel and user mode
- monitor catches traps and simulates them to the VM
virtual memory
- maintains machine-to-physical mapping
- catches VM attempts to update the TLB and uses them to update it's own TLB
-
downsides which decrease performances
- TLB used for OS code/memory
- TLB flushed between CPU switches
memory management
-
tries to be smart
- copies pages to the nodes where they are most used
- duplicates read-heavy pages between nodes that use them
- uses FLASH hardware support for counting cache misses per page and identifying hot pages
I/O devices
- intercepts all devices access
- add special DISCO device drivers into the OS
- DMA map (translates physical to virtual address spaces?)
copy-on-write disks
- multiple VMs can share pages in virtual memory
- copy-on-write means that this is transparent to the machines
- copy-on-write only makes sense for writes which will not be permanent or shared between machines
- user files and persistent disks DISCO only allows one VM to mount the disk at a time (or using distributes file system protocol like NFS)
DISCO (commodity OS)
currently supports a version of UNIX (IRIX), most changes to the OS resided in the HAL (hardware abstraction layer)
the special load/store call mentioned earlier to avoid traps are implemented in the HAL
experimentation
all takes place on SimOS a machine simulator
conclusion
developing system software for shared-memory multiprocessors, and more generally for new hardware.
DISCO shows that many of the performance limitations of VM setups are no longer an issue (sort of).
although software and OSs are growing in complexity the hardware-interface has remained relatively simple. supporting new hardware through a thin VM monitor such as disco is simpler and easier then rewriting the OS.
question
- DMA
- what is it?
Xen and the Art of Virtualization
Exokernel
don't hide power!
Allows untrusted user-level applications to have direct access to system hardware. They present ExOS, an operating system implemented entirely in user-space libraries.
does this by securely multiplexing hardware resources between untrusted software
many programs have specialized behavior and their performance is severely hampered by being forced into using general OS abstractions to access hardware
library OS
- libraries implementing some part of the OS can be app specific
- libraries can trust the application (the exokernel will errors from hurting other applications)
- less OS-app transitions since much of the OS (the library) is in the application's address space
exokernel requirements
- track ownership of resources
- performing access control (guarding usage or binding points)
- revoking access to resources
revocation
most OSs have invisible revocation of resources, so that application doesn't know when for example physical memory is being allocated or deallocated.
exokernels have visible revocation, so that applications can have some say in their allocation, and know when resources are scarce. even when the processor is taken at the end of a time-slice the application is notified.
this is necessary when the applications are using physical names to refer to resources, they must be notified upon revocation because their names will have to change
sometimes it's nice to allow "good faith" operations to take place before revocation of a resource
other times the exokernel will abort a misbehaving application
implementations
- Aegis
- exokernel
- ExOS
- Library OS
Aegis
- process environments
-
store the information needed to deliver
events associated with a resource to it's owner
- exception
- interrupt
- protected entry
- addressing
exceptions
transfers all exceptions to the application except system calls and interrupts
exception handling…
- saves three "scratch" registers into an agreed upon place
- loads the exception program counter, last non-valid virtual page address, and cause of exception
- uses exception cause to jump to pre-specified application program counter where processing resumes
features
- very fast
- very simple (because does not have to differentiate between TLB exceptions and all others)
address translation (application level virtual memory)
TODO
summary
an exokernel eliminates high level abstractions and focuses purely on securely multiplexing the hardware. a library OS can be build very efficiently upon an exokernel providing many of the standard OS features in a fast and extensible manner.
by allowing applications direct access to hardware it is possible for applications to greatly speed up their performance as compared to a traditional OS.
by implementing the majority of the OS as application libraries it is trivial to extend or tailor major components of the OS.
the only downside seems to be that the application has much more to worry about if it wants to take advantage of the potential speedup.
µ-kernels
performance-of-µ-kernel-based-systems
This paper aims to show that µ-kernel systems
- can run modern OS personalities
- can perform in the same range as normal monolithic kernels
- that extensions to µ-kernel based systems can be implemented efficiently in user space
- supports four basic processes; address-spaces, threads, scheduling, and synchronous inter-process communication
intro
- a µ-kernel only provides address space, threads, and IPC
-
many people think that µ-kernels are either
- too low
- and these people try to add safeguards, or abstractions for helping extensions
- too high
- and these people try to make µ-kernel interfaces look like hardware interfaces
-
first generation µ-kernels like Chorus and Mach
- evolved from monolithic kernels
-
second generation µ-kernels like QNX and L4
- designed form scratch
- more rigorous in pursuit of minimalist design
-
experiments
-
linux adapted to run on L4
- gives upper performance bound
- compare L4Linux to a linux adapted to the Mach kernel
- insight to µ-kernel functions that affect linux performance
- implemented pipes on top of µ-kernel and compared to native unix pipes
- implemented mapping-related OS extensions
- implemented first part of real time user-level memory management system
- moved the L4 to a new processor
- lower-level communication primitive
-
linux adapted to run on L4
related work
L4 essentials
based on two basic concepts, threads and address spaces
- thread
- activity executing inside of an address space
- IPC
- cross address-space communication is a fundamental µ-kernel mechanism
the initial address space represents physical memory, additional address spaces are constructed by granting, mapping, and unmapping flex-pages of sizes 2n. the owner of an address space can grant map and unmap it's pages to/from other address spaces. these user-level pagers handle all address space construction and maintenance.
- note
- mapping and unmapping pages is like creating and deleting pages. mapped to physical memory or not
when there is a page-fault it is IPC'd by the µ-kernel to the pager associated with the faulting thread. the pager and thread have complete control as to how to handle the fault allowing many options for memory management
I/O ports are handled as address spaces, with device interrupts handled as IPC
exceptions and traps are synchronous to the executing thread, they are mirrored up to user-level
linux on L4
as linux now runs on multiple architectures there is a fairly well-defined interface between architecture dependent and independent sections
-
architecture-defendant section
- interrupt service routine
- low-level device driver support
- user process interaction
- context switching
- copyin/copyout data between kernel and user spaces
- signaling
- mapping/unmapping of address spaces
- system-call mechanism
- linux uses a 3-level architecture independent page-table scheme
L4-linux design/implementation
- fully binary compliant
µ-kernel tasks are used for user processes and provide linux services via a single linux server in a separate µ-kernel task.
- the linux server
- linux kernel's address space maps 1-1 to the underlying pager
Unix Time Sharing System
wish I had read this to learn Unix/Posix systems
-
perhaps the most important achievement is demonstration of cheap
- $40,000 in hardware
- 2 man-years in development
- UNIX takes ~50K of ~144K of memory on the computer
- originally implemented largely in byte code, now all in C
File System
- ordinary files
- directories
- special files
types of files
- ordinary files: can hold any content, the file system places no limits
-
directories: fairly elegant specification of directories, each is a
file holding the names of the files it contains, there is a root
directory, there is normally a current directory, etc…
-
/is the "root" directory, which holds a path to all files -
there are links (a file can live in multiple directories)
- all links are equal (it doesn't actually live in any one) although in practice a file is made to disappear along with it's last link.
-
.and..are special
-
-
special files: each I/O device is associated with a special file
through which reading/writing to the I/O device occurs
- file/device I/O are as similar as possible
- file/device names have the same syntax and meaning
- same protection mechanism
- mount: system call which takes the name of an existing ordinary file, and the name of a special file which points to a device which has the structure of an independent file system. mount then replaces the existing file with the root of the independent file system. mounted file systems are identical to regular file systems with the single caveat that no links can exist between separate file systems.
protection
- uid: each user assigned a unique id
- 7 permission bits: 6 of which contain read/write/execute info for owner and all other users. 7th when set means that whenever the file is executed it is done so as the owner regardless of the user who triggered the execution.
- super-user one user ID is exempt from all protections
I/O
- no locks (they don't really help)
- sequential access (systems keep a progress-pointer for each file)
- possible to seek through the file
- read/write calls return the number of bytes read/written
implementation
Each directory entry contains both the name and i-number for the related file.
-
the i-number is an index into the system table i-list which
identifies the file's i-node which contains the following
- owner
- protection bits
- physical address of file
- size
- time-of last modification
- number of links (number of referencing directories)
- directory bit
- special bit
- large/small bit
-
ordinary files: the space on all storage is divided into 512-byte blocks
- a small file fits into 8 or less blocks and the block addresses are stored
- a large file uses the 8 blocks to hold 256 block addresses each allowing for file as large as 220 bytes
-
special files: first address word is used to indicate
- device type: determines drivers used etc…
- sub-device number: indicates which of the possible devices it is
all reading/writing appears as unbuffered and sync to user (it actually is buffered)
efficiency
The time was divided as follows: 63.5 percent assembler execution time, 16.5 percent system overhead, 20.0 percent disk wait time. We will not attempt any interpretation of these figures nor any comparison with other systems, but merely note that we are generally satisfied with the overall performance of the system.
Processes and Images
- image: computer execution environment, core, registers, current directory, etc…
- process: execution of an image
The user-core has three parts
- program text
- non-shared writable segment (heap)
- stack
processes
fork creates a process
processid = fork(label)
makes two identical copies of a process differentiated only in that
the parent returns control directly while in the child control is
passed to label. the return processid is the id of the other
process.
pipes
interprocess communication uses same read/write calls used for files, only the info passes through a pipe
filep = pipe
a read on a pipe blocks until someone else writes to the same pipe
execution of programs
execute(file, arg, arg, ..., arg)
all code and data is replaced with that read from file
execute only returns if the execution fails (couldn't find file, or file is not executable)
process synchronization
processid = wait( )
suspends execution until a child process terminates, at which point the id of the child is returned.
termination
exit(status)
terminates a process destroying it's image. status is available to
any ancestor which is waiting
processes also terminate from illegal actions or due to user signals
The Shell
take command lines and uses them to execute files with arguments.
standard I/O
programs run by the shell have two files (STDIN and STDOUT) which
would be the terminal, but can be redirected to files using < and
>.
these are intercepted by the shell and aren't passed as arguments to the program.
filters
commands separated by the | character are run simultaneously with
the output of the left program sent to the input of the right
program.
filters are commands which copy (with alteration) their standard input to their standard output
command separators & multitasking
-
;can be used to separate multiple commands on a line -
&can be used to run commands in the background
shell as command: command file
the shell is itself a command, and series of shell commands can be written to files (shell scripts)
implementation
- command passed to shell
- parsed into command and arguments
- fork is called
- child calls execute
- parent waits for child, then re-prints prompt
a-synch running is trivial (don't wait)
when child forks it inherits all open files from it's parent (including STDIN and STDOUT)
redirects > simply mean child changes it's file descriptors before
calling execute
filters use pipes instead of files
shell only terminates when it sees an end-of-file in it's input
initialization
last step in Unix booting is calling executing the init command. init creates one process per available typewriter channel, each of these processes types out a login screen, and waits for a user. the init parent waits for a termination at which point it creates a new process for that typewriter channel and prints another login screen.
password file is checked after a user tries to log in. It contains a username, password, and the shell (or other program) to be run.
Traps
when illegal action is caught the program terminates, and it's image
is written to the file core in the current directory
programs can be halted by sending the interrupt signal, which halts
execution and does not write out the image to file
the quit signal is like interrupt but it does write out a core
file
these hardware/user signals can be ignored or caught allowing programs (like shells or editors) to continue operation
Perspective
no predefined objectives, simply written on a spare computer for personal use with goal of a "comfortable relationship with the machine"
3 considerations (in retrospect)
-
designed to write programs interactively.
- interactive use is more fun than batch
- initially only built for one user
- size constraints on system lead to economy and elegance
- from the beginning the system maintained itself, designers were using the system from the very beginning
since all programs need to be operable with any file/device it places all device-drivers into the OS
since the shell is just a user program it is easy to enhance, and actions like forking, redirection, background execution etc… are trivial
influences
not new ideas, but selection of particularly fertile ideas
- fork from Berkeley
- I/O routines from Multics
- shell from Multics
Statistics
see paper for stats, presumably these are impressive
Observations on the Development of an Operating System
Observations on the Development of an Operating System
-
hypotheses
- Operating Systems can be divided into five kinds according to the style and direction of their development, independent of their structure.
- OS's take about 5-7 years to develop
- focus on life-cycle of OS development, with the running example of the Pilot OS developed at IBM
summary: No matter what you might think, or how disciplined your team going in. When trying to build an new OS to be used by clients which represents a major step away from existing OSs there will be delays, and bloat. Expect 5-7 years before the system will be mature or useful or able to survive in the wild on its own.
Pilot
- kernel: 25,000 to 50,000 lines of Mesa code
-
system development project: 250,000 lines of Mesa
- kernel
- debugger
- compilers
- librarian tools, etc…
- framework for thinking about designing/implementing systems for inter-subsystem and inter-computer communication
focus on 2nd meaning
Problems
size of the system: initially the kernel dominated the system size, but as outside functionality was absorbed and new tasks (development, running for multiple clients, etc…) added the system bloated both in and outside of the kernel
working set sizes: amount of real memory required to handle virtual memory without thrashing. Problems caused by the lull of virtual memory and lack of real feedback.
- the working set of the kernel was almost constant across releases
- at one point using more than double allowable working memory
programmer productivity: impossible to measure
holy wars:
- processes and monitors v.s. message passing
- different file system access systems
virtual memory system: based on assumption that disk access was very slow (this in the end was not the case). would have been almost as efficient to treat the disk as synchronous rather than jump through the many complex hoops built for async disk access
pipes filters and streams: Mesa streams are supposed to be like unix pipes. These streams are rarely used because Mesa is more of a type-safe API based language.
Comparing Pilot and other OSs
5 system types
-
favorite systems (e.g. unix)
- hugely successful
- develop a large user community outside of their developer base
- begin life as simple unambitious projects
- grow because new outside users find them easy to extend
-
planned systems
- cut from whole cloth
- generally with organizational backing
- goals/structures are the product of up front negotiations (not organic growth)
- some succeed and some don't
-
branches of existing systems
- major changes from existing system, but still able to borrow much supporting software
-
laboratory systems
- make contributions to the "art and science" of OS design
- never gain large user base
- worthless systems
Five to Seven year rule
For planned systems of the second kind expect 5-7 years before reaching a viable OS.
time-line
- planning design
- initial implementation: no OS clients so little to no testing/feedback
- initial functionality: some hardy users begin cutting through the forests of bugs and issues
- painful refinement, making users happy
- client buy in: if reached, this is when the community starts adapting to and adding to the OS
Systems of the second time almost have to bee too ambitious or general for anyone to finance them. Hence the propensity for overrun deadlines or outright failure.
Hints for Computer System Design
Hints for Computer System Design
Collection of hints gathered from the Authors experience building a variety of systems.
Most important hints deal with interfaces which should
- be simple
- be complete
- admit a sufficiently small and fast implementation
Keep it simple
Perfection is reached not when there is no longer anything to add, but when there is no longer anything to take away. (A. Saint-Exupery)
- don't try to put too much into an interface
- do one thing and do it right
- don't try to generalize too much
- don't spend time making something fast unless it's really needed
-
get it right
- don't expose functionality which if used will probably be used poorly
-
do it fast
- a fast operation (if available/usable) is probably better than a powerful one
- programs spend most of their time doing very simple things (loads, stores, incrementing, etc…)
-
don't hide power
- if something works well and is useful at a low level, don't build abstractions on top of it
-
use procedure (functional) arguments
- rather than defining a language of static arguments/options which then result in the procedure. (e.g. map, filter, etc…)
-
leave it to the client
- relates to simplicity, only encode what is needed in every case in the interface, for the rest let the client built what she needs
- unix, each command does one thing well, and the client connects them together
Continuity
- keep basic interfaces stable
-
keep a place to stand
- by implementing the old interface on top of the new one
- word-swap debuggers, which re-create the memory on disk for stopping, inspecting, and restarting
Making implementations work
-
plan to throw one away
- if you're doing something novel you will burn through at least one unusable prototype
-
keep secrets
- assumptions of implementation that clients are not allowed to make
- tension here with not hiding power
An efficient program is an exercise in logical brinkmanship. (E. Dijkstra)
-
divide and conquer
- recursive or bite-by-bite
-
use a good idea again
- instead of generalizing it
Handling all the cases
-
handle normal and worst cases separately
-
different requirements
- normal must be fast
- worst must be possible
-
different requirements
Speed
- split resources in a fixed way if in doubt (easier then sharing)
-
use static analysis when possible
- static analysis is analysis which doesn't require that the code be run
-
dynamic translation can be helpful.
- translation in incremental steps between convenient readable representations to those that can be easily evaluated
- cache answers to expensive computations
- use hints like cached answers but they may be wrong and this can be checked
-
when in doubt use brute force don't be too fancy, don't work
around assumptions which may not hold
- special purpose hardware (e.g. FPGA)
- compute in background take advantage of the lulls in activity
- batch processing when you can do it all at once (rather than incrementally) then it will probably be easier and more reliable
- safety first strive to avoid disaster before incrementally improving performance
- shed load if demand is outstripping resources, begin dropping clients
Fault-tolerance
The unavoidable price of reliability is simplicity. (C. Hoare)
-
end-to-end
Error recovery at the application level is absolutely necessary for a reliable system, and any other error detection or recovery is not logically necessary but is strictly for performance. – Saltzer
- intermediate checks only serve performance
- log updates it's cheap, reliable, and useful (like a transactional database)
- make actions atomic or restartable
Conclusion
done
project
TODO paper [2/4]
- [X] go over 3-sched
- [] Con and LKML background
- [X] data analysis
- [] look over results
BFS vs. CFS
Con vs. Ingo Molnar
according to Con Kolivas
- BFS is simpler – ~9000 less lines of code than CFS
- more appropriate for the loads of normal interactive desktop users
- single runqueue -> much easier to gaurentee global fairness
- no heuristics which try to guess interactivity from analysis of sleep time
-
interactive tasks will naturally be scheduled with high priority because:
- if they're just waking up then they haven't used up their CPU time
- they will have earlier effective deadlines
according to Ingo Molnar
people are regularly testing 3D smoothness, and they find CFS good enough and that matches my experience as well (as limited as it may be). In general my impression is that CFS and SD are roughly on par when it comes to 3D smoothness.
there was simply no code in existence before CFS which has proven the code simplicity/design virtues of 'fair scheduling' - SD was more of an argument against it than for it. I think maybe even Con might have been surprised by that simplicity: in his first lkml reaction to CFS he also wrote that he finds the CFS code 'beautiful', and my reply to Con's mail still addresses a good number of points raised in this thread i think.
Linus on choosing CFS over SD
-
Con can't be trusted to maintain his code
that was where the SD patches fell down. They didn't have a maintainer that I could trust to actually care about any other issues than his own.
as a long-term maintainer, trust me, I know what matters. And a person who can actually be bothered to follow up on problem reports is a hell of a lot more important than one who just argues with reporters
SD (Staircase Deadline) Scheduler
- http://kerneltrap.org/SD_scheduler
-
http://lwn.net/Articles/231973/
- It has bound latency. CFS can't guarantee either as well as SD can. SD allows one to set the exact scheduling priority of everything and it is always respected, as there is no interactive renicing: it is very predictable.
Brain Fuck Scheduler
-
http://ck.kolivas.org/patches/bfs/bfs-faq.txt
- Testing this scheduler vs CFS with the test app "forks" which forks 1000 tasks that do simple work, shows no difference in time to completion compared to CFS. That's a load of 1000 on a quad core machine.
timeline
- 1999 Con gets into linux, and at around 2.4.18 he began preparing his own patches merging desktop-performance patches to the kernel (e.g. O1, preempt, low latency and compressed cache)
-
ck patchset seems to do great things for interactive kernel use
One thing is for sure, the -ck patches before that one did an increadible job. Still, many years and hardware generations after, the best performing system I ever had (as in user experience, gapless audio playback while copying large and many files, …) was a 300 MHz Pentium II with probably 512 MB RAM running a 2.4 -ck kernel.
My current systems still have gaps in Audio playback even though they are running at 1.8 GHz and more.
I wish back my old system, just for playing audio.
-
2002 Con is interviewed about
ConTest(see here) a benchmarking tool which is heavily used by kernel developers - 2004 Con releases the Staircase scheduler (see here) (see this email)
- Early 2007 Rotating Staircase Deadline scheduler (see here)
-
Linus seems amenable to RSDS mainline inclusion
I agree, partly because it's obviously been getting rave reviews so far, but mainly because it looks like you can think about behaviour a lot better, something that was always very hard with the interactivity boosters with process state history.
- the Staircase scheduler develops into the SD (Staircase Deadline) scheduler
- early 2007 Ingo Molnar releases his own rewrite of Con's SD scheduler to much acclaim (see this node)
- Cons is not pleased (see this email)
-
mid 2007 Con stops updating the -ck patchset (see this email)
It is clear that I cannot develop code for the linux kernel intended only to be used out of mainline and not have mainline get involved somewhere along the line. Whether it be the users or even other developers repeatedly asking "when will this be merged". This forever gets me into a cycle of actually trying to merge the stuff and … well you all know what happens at that point (again I had nastier words but decided not to use them.)
So, I've had enough. I'm out of here forever. I want to leave before I get so disgruntled that I end up using windows. I may play occasionally with userspace code but for me the kernel is a black hole that I don't want to enter the event horizon of again.
-
Ingo responds to Con's release 2009-09-06 (see this email)
I understand that BFS is still early code and that you are not targeting BFS for mainline inclusion - but BFS is an interesting and bold new approach, cutting a lot of code out of kernel/sched*.c, so it raised my curiosity and interest :-)
Alas, as it can be seen in the graphs, i can not see any BFS performance improvements, on this box.
So the testbox i picked fits into the upper portion of what i consider a sane range of systems to tune for - and should still fit into BFS's design bracket as well according to your description: it's a dual quad core system with hyperthreading.
-
Con responds 2009-09-07 (see this email)
/me sees Ingo run off to find the right combination of hardware and benchmark to prove his point.
[snip lots of bullshit meaningless benchmarks showing how great cfs is and/or how bad bfs is, along with telling people they should use these artificial benchmarks to determine how good it is, demonstrating yet again why benchmarks fail the desktop]
I'm not interested in a long protracted discussion about this since I'm too busy to live linux the way full time developers do, so I'll keep it short, and perhaps you'll understand my intent better if the FAQ wasn't clear enough.
Do you know what a normal desktop PC looks like? No, a more realistic question based on what you chose to benchmark to prove your point would be: Do you know what normal people actually do on them?
Feel free to treat the question as rhetorical.
notes
real tests
function latt-results(base="base"):
results = Dir.entries(File.join(base)).map do |e| if e.match(/.*out(\d+).*/) [Integer($1)] + File.read(File.join(base, e)).map do |l| Integer($1) if l.match(/.*?(\d+) *usec.*/) end.compact end end.compact
data.each{ |l| puts "|"+l.join(" | ")+"|" }
| 1 | 3847 | 124 | 446 | 39 | 136903 | 100383 | 5966 | 515 |
| 2 | 20030 | 955 | 2430 | 155 | 219031 | 137104 | 13517 | 862 |
| 3 | 73647 | 13612 | 21009 | 1173 | 383096 | 174236 | 28855 | 1611 |
| 4 | 109658 | 21506 | 25827 | 1318 | 341028 | 226312 | 34078 | 1739 |
| 5 | 148674 | 27177 | 31495 | 1519 | 395191 | 281150 | 37515 | 1809 |
| 6 | 148416 | 33376 | 38127 | 1751 | 476689 | 333882 | 45291 | 2080 |
| 7 | 223346 | 37809 | 43699 | 1960 | 525645 | 396762 | 50692 | 2274 |
| 8 | 251356 | 43688 | 53118 | 2312 | 654439 | 454026 | 53991 | 2350 |
| 9 | 234711 | 47452 | 52388 | 2218 | 668008 | 512374 | 57961 | 2454 |
| 10 | 268947 | 50518 | 56947 | 2344 | 756613 | 567916 | 63370 | 2609 |
data.each{ |l| puts "|"+l.join(" | ")+"|" }
| 1 | 3675 | 69 | 325 | 26 | 49456 | 31094 | 2965 | 236 |
| 2 | 15451 | 188 | 1224 | 69 | 54753 | 31353 | 3027 | 171 |
| 3 | 44760 | 5873 | 8952 | 423 | 82646 | 40487 | 12700 | 601 |
| 4 | 46814 | 8432 | 10647 | 439 | 87481 | 47902 | 13865 | 572 |
| 5 | 73662 | 12727 | 14015 | 534 | 136676 | 56542 | 17872 | 680 |
| 6 | 62503 | 14414 | 14475 | 505 | 154784 | 65107 | 17297 | 603 |
| 7 | 116681 | 20178 | 19589 | 649 | 175359 | 76453 | 24407 | 809 |
| 8 | 110105 | 22831 | 21448 | 673 | 195287 | 81819 | 23305 | 731 |
| 9 | 124869 | 25198 | 23156 | 693 | 165885 | 89315 | 25439 | 761 |
| 10 | 157668 | 27586 | 24549 | 706 | 164980 | 96154 | 27432 | 789 |
| 11 | 154270 | 31515 | 27226 | 759 | 189019 | 106003 | 29155 | 813 |
| 12 | 204609 | 39826 | 35900 | 971 | 233421 | 106114 | 34894 | 943 |
| 13 | 168486 | 40721 | 34658 | 912 | 219374 | 120001 | 34546 | 909 |
| 14 | 163194 | 41588 | 33267 | 852 | 248706 | 128874 | 35918 | 919 |
| 15 | 203498 | 45197 | 37336 | 936 | 308278 | 141872 | 39753 | 997 |
| 16 | 213616 | 47945 | 38915 | 954 | 245362 | 147306 | 41478 | 1017 |
| 17 | 232214 | 52437 | 42495 | 1031 | 304720 | 157500 | 44672 | 1083 |
| 18 | 261034 | 58236 | 49930 | 1195 | 298037 | 158504 | 49982 | 1196 |
| 19 | 250611 | 58823 | 46255 | 1083 | 303229 | 172885 | 47975 | 1123 |
| 20 | 279880 | 57325 | 44428 | 1019 | 369985 | 186997 | 48912 | 1122 |
data.each{ |l| puts "|"+l.join(" | ")+"|" }
| 1 | 3675 | 69 | 325 | 26 | 49456 | 31094 | 2965 | 236 |
| 2 | 3603 | 81 | 333 | 19 | 50891 | 33909 | 3094 | 175 |
| 3 | 14977 | 1621 | 3119 | 147 | 63231 | 45225 | 4787 | 226 |
| 4 | 16288 | 3554 | 4621 | 191 | 78503 | 57241 | 5906 | 244 |
| 5 | 21650 | 5059 | 5668 | 214 | 101637 | 69758 | 7882 | 298 |
| 6 | 31288 | 6901 | 6948 | 244 | 115349 | 81085 | 8248 | 290 |
| 7 | 36701 | 8897 | 8525 | 283 | 132428 | 93030 | 10158 | 337 |
| 8 | 42805 | 10986 | 9876 | 311 | 151479 | 104323 | 11902 | 375 |
| 9 | 43571 | 12718 | 10766 | 324 | 168803 | 116987 | 13642 | 410 |
| 10 | 57919 | 15239 | 12198 | 355 | 184954 | 128700 | 14682 | 427 |
| 11 | 55153 | 16664 | 13189 | 372 | 206221 | 141415 | 17527 | 495 |
| 12 | 61766 | 18789 | 14428 | 394 | 230900 | 148623 | 15859 | 433 |
| 13 | 73299 | 20834 | 15409 | 409 | 244328 | 163776 | 19161 | 509 |
| 14 | 68849 | 22847 | 16692 | 433 | 258783 | 175110 | 19890 | 516 |
| 15 | 74255 | 24603 | 17802 | 453 | 267375 | 184825 | 21259 | 541 |
| 16 | 94934 | 27876 | 19536 | 488 | 307184 | 198535 | 25055 | 626 |
| 17 | 90519 | 30494 | 21592 | 532 | 319140 | 210595 | 28265 | 696 |
| 18 | 93456 | 32464 | 22524 | 545 | 341838 | 218002 | 29598 | 716 |
| 19 | 106604 | 36042 | 25485 | 616 | 367055 | 239063 | 40259 | 974 |
| 20 | 116848 | 38833 | 27290 | 654 | 389510 | 257751 | 44943 | 1077 |
test – new kernel
only taking stats from the first run as latt.c already does multiple runs for us and calculates error bars, etc…
results = Dir.entries(File.join(base)).map do |e| if e.match(/.*out(\d+).*/) [Integer($1)] + File.read(File.join(base, e)).map do |l| Integer($1) if l.match(/.*?(\d+) *usec.*/) end.compact end end.compact
| 1 | 3847 | 124 | 446 | 39 | 136903 | 100383 | 5966 | 515 |
| 2 | 20030 | 955 | 2430 | 155 | 219031 | 137104 | 13517 | 862 |
| 3 | 73647 | 13612 | 21009 | 1173 | 383096 | 174236 | 28855 | 1611 |
| 4 | 109658 | 21506 | 25827 | 1318 | 341028 | 226312 | 34078 | 1739 |
| 5 | 148674 | 27177 | 31495 | 1519 | 395191 | 281150 | 37515 | 1809 |
| 6 | 148416 | 33376 | 38127 | 1751 | 476689 | 333882 | 45291 | 2080 |
| 7 | 223346 | 37809 | 43699 | 1960 | 525645 | 396762 | 50692 | 2274 |
| 8 | 251356 | 43688 | 53118 | 2312 | 654439 | 454026 | 53991 | 2350 |
| 9 | 234711 | 47452 | 52388 | 2218 | 668008 | 512374 | 57961 | 2454 |
| 10 | 268947 | 50518 | 56947 | 2344 | 756613 | 567916 | 63370 | 2609 |
work errorbars
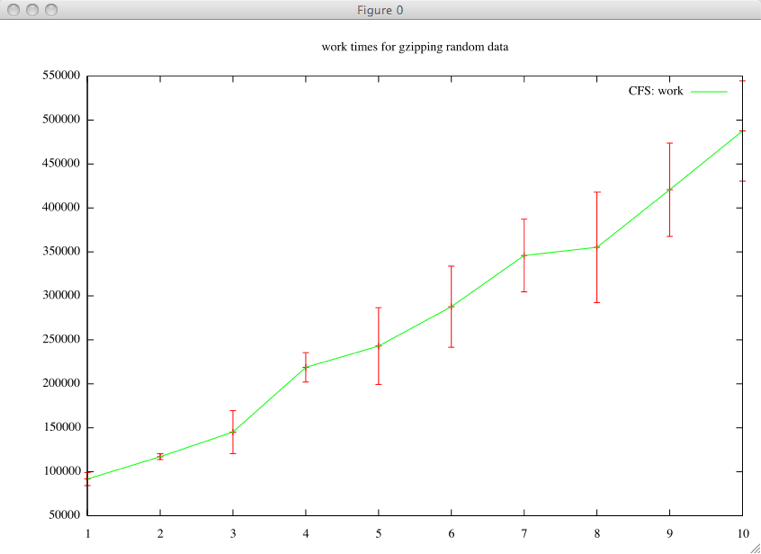
frame drops
base = "./project/2.6.31.6_hausmaster-laptop/av/" results = Dir.entries(File.join(base)).map do |e| if e.match(/out(\d+).txt/) [Integer($1)] + File.read(File.join(base, e)).map do |l| (l.match(/V\:(\d+)\:(\d+)/)) ? [Float($1), Integer($2)] : nil end.compact.map{|l,r| [100-((r / (l+1))*100)] }.last end end.compact.each{ |l| puts "|"+l.join(" | ")+"|" }
| 1 | 100.0 |
| 2 | 99.8543335761107 |
| 3 | 99.4147768836869 |
| 4 | 98.3618763961281 |
| 5 | 97.6761619190405 |
| 6 | 96.6565349544073 |
| 7 | 94.296875 |
| 8 | 93.7795275590551 |
| 9 | 94.5797329143755 |
| 10 | 92.0255183413078 |
actually running some tests
base = "./project/bfs" results = Dir.entries(base).map do |e| if e.match(/i(\d+).out/) [Integer($1)] + File.read(File.join(base, e)).split("\n").map do |l| Integer($1) if l.match(/.*?(\d+) *usec.*/) end.compact end end.compact.each{ |l| puts "|"+l.join(" | ")+"|" }
base = "./project/bfs" Dir.entries(base).map do |e| if e.match(/i(\d+).out/) [Integer($1)] + File.read(File.join(base, e)).map{|l| Integer($1) if l.match(/.*?(\d+) *usec.*/)}.compact end end.compact.each{ |l| puts "|"+l.join(" | ")+"|" }
work errorbars
wakeup errorbars
all on one
jeff's results
| 1 | 322 | 11 | 26 | 2 | 40858 | 33434 | 2926 | 234 |
| 2 | 15778 | 3439 | 4858 | 284 | 93302 | 57327 | 7113 | 416 |
| 3 | 31602 | 7273 | 7675 | 381 | 122543 | 81251 | 10231 | 508 |
| 4 | 47619 | 11256 | 10508 | 468 | 146941 | 107658 | 12848 | 572 |
| 5 | 55621 | 15068 | 12915 | 529 | 179079 | 126734 | 17147 | 703 |
| 6 | 78896 | 20132 | 16834 | 652 | 224041 | 153557 | 21634 | 838 |
| 7 | 79376 | 24201 | 18530 | 683 | 261242 | 175972 | 24642 | 909 |
| 8 | 99925 | 28032 | 21225 | 758 | 300960 | 205240 | 32233 | 1151 |
| 9 | 102309 | 32829 | 24116 | 829 | 341542 | 226719 | 36207 | 1245 |
| 10 | 122910 | 38026 | 27450 | 931 | 378846 | 256072 | 41322 | 1401 |
| 1 | 39 | 11 | 3 | 0 | 63212 | 45110 | 3734 | 303 |
| 2 | 37330 | 9829 | 10733 | 648 | 123717 | 75794 | 15559 | 940 |
| 3 | 50036 | 16725 | 14469 | 744 | 166951 | 103040 | 20449 | 1052 |
| 4 | 60771 | 20001 | 16194 | 739 | 196976 | 121333 | 25811 | 1178 |
| 5 | 99898 | 26263 | 20435 | 860 | 222647 | 138132 | 30665 | 1290 |
| 6 | 125911 | 32808 | 24503 | 967 | 276826 | 159907 | 38284 | 1511 |
| 7 | 136318 | 38887 | 27918 | 1040 | 301758 | 173934 | 43273 | 1612 |
| 8 | 168979 | 44304 | 31485 | 1130 | 348513 | 192425 | 52425 | 1882 |
| 9 | 193398 | 49936 | 34993 | 1203 | 376297 | 206254 | 54942 | 1889 |
| 10 | 208970 | 56251 | 39117 | 1304 | 428826 | 219508 | 63024 | 2101 |
work errorbars
wakeup errorbars
taylor results
| 1 | 48 | 29 | 11 | 5 | 89117 | 88696 | 356 | 159 |
| 2 | 38317 | 9162 | 14364 | 5078 | 183274 | 157032 | 15264 | 5397 |
| 3 | 19015 | 3625 | 6949 | 2006 | 237982 | 163345 | 37587 | 10850 |
| 4 | 40082 | 7297 | 11816 | 2954 | 297934 | 218751 | 45478 | 11369 |
| 5 | 56967 | 12006 | 19883 | 5134 | 370527 | 299750 | 34033 | 8787 |
| 6 | 197095 | 29112 | 52762 | 12436 | 378163 | 320431 | 53987 | 12725 |
| 7 | 62656 | 18670 | 17292 | 3773 | 438030 | 400260 | 23497 | 5128 |
| 8 | 153654 | 29389 | 44716 | 9128 | 528557 | 417398 | 51049 | 10420 |
| 9 | 135979 | 43330 | 40470 | 7788 | 555059 | 466411 | 78488 | 15105 |
| 10 | 242612 | 42873 | 68167 | 12446 | 628015 | 475800 | 87386 | 15954 |
| 1 | 55 | 29 | 15 | 7 | 89662 | 89019 | 418 | 187 |
| 2 | 4736 | 1230 | 1794 | 634 | 149805 | 144967 | 3243 | 1147 |
| 3 | 7269 | 2684 | 2687 | 776 | 216993 | 202884 | 9159 | 2644 |
| 4 | 17619 | 5140 | 5474 | 1369 | 274191 | 256837 | 13168 | 3292 |
| 5 | 16372 | 6463 | 5778 | 1492 | 326104 | 307699 | 16855 | 4352 |
| 6 | 21754 | 10716 | 7862 | 1853 | 391064 | 360888 | 25385 | 5983 |
| 7 | 22960 | 10366 | 7590 | 1656 | 463452 | 427938 | 30555 | 6668 |
| 8 | 43914 | 16872 | 12730 | 2598 | 511854 | 477101 | 26558 | 5421 |
| 9 | 43543 | 15306 | 10991 | 2115 | 565166 | 534687 | 24529 | 4721 |
| 10 | 32396 | 12250 | 10698 | 2392 | 641921 | 602982 | 38807 | 8677 |
work errorbars
wakeup errorbars
results of the initial short run
| clients | max | avg | stdev | stdev mean | max | avg | stdev | stdev mean |
|---|---|---|---|---|---|---|---|---|
| 1 | 32 | 26 | 3 | 1 | 45521 | 40912 | 9169 | 4101 |
| 2 | 4618 | 491 | 1450 | 459 | 46845 | 45910 | 1374 | 434 |
| 3 | 35772 | 7188 | 12617 | 3258 | 66012 | 47203 | 12731 | 3287 |
| 4 | 47612 | 11190 | 13993 | 3129 | 92774 | 62032 | 20679 | 4624 |
| 5 | 78830 | 24899 | 27926 | 5585 | 99364 | 49770 | 17919 | 3584 |
| 6 | 53154 | 15118 | 14660 | 2676 | 114770 | 69815 | 20333 | 3712 |
| 7 | 55765 | 12266 | 18432 | 3483 | 121098 | 59936 | 20165 | 3811 |
| 8 | 61666 | 17244 | 20994 | 3711 | 135540 | 73728 | 34408 | 6083 |
| 9 | 98198 | 29768 | 28730 | 4788 | 149886 | 80922 | 32844 | 5474 |
| 10 | 119101 | 18923 | 30233 | 4780 | 164823 | 68145 | 41851 | 6617 |
| clients | max | avg | stdev | stdev mean | max | avg | stdev | stdev mean |
|---|---|---|---|---|---|---|---|---|
| 1 | 52 | 25 | 14 | 6 | 34052 | 31043 | 2882 | 1177 |
| 2 | 121 | 35 | 31 | 9 | 32951 | 30427 | 1652 | 477 |
| 3 | 7962 | 1149 | 2508 | 648 | 44959 | 41041 | 2498 | 645 |
| 4 | 12155 | 2068 | 3109 | 695 | 68560 | 56283 | 8685 | 1942 |
| 5 | 13584 | 4795 | 4967 | 993 | 75826 | 66148 | 8812 | 1762 |
| 6 | 21760 | 6601 | 7203 | 1315 | 86005 | 73206 | 8718 | 1592 |
| 7 | 19290 | 7422 | 6676 | 1128 | 107545 | 87649 | 8881 | 1501 |
| 8 | 42266 | 10625 | 10161 | 1607 | 110436 | 92718 | 14027 | 2218 |
| 9 | 40445 | 13647 | 11335 | 1690 | 134468 | 100833 | 18010 | 2685 |
| 10 | 31040 | 13661 | 10206 | 1614 | 136177 | 116693 | 9188 | 1453 |
building the kernel
initial build
- cd into the kernel directory
-
copy your local configuration into the kernel config
cp /boot/config-`uname -r` ./.config -
run the menuconfig
make menuconfig
select the "load configuration" option, load your the
.configfile, and then exit -
now you can try to make the kernel with
make -
install the build tools, and header files
sudo apt-get install build-essential linux-headers-2-...
- still didn't work, then switched to the unstable debian repos (replaced "lenny" with "unstable" in /etc/apt/sources.list)
-
with unstable I installed
libc6-devand tried again -
now missing
zlibinstead ofeventfd.h -
installing
zlibsudo apt-get install zlib1g-dev
-
make the kernel
make menuconfig. This spits out the following error message, but seems to succeed regardlessmake[1]: *** No rule to make target `just'. Stop. make: [Just] Error 2
- now make the Debian kernel package
-
install the resulting .deb file
dpkg -i linux-image......
- rebooted using the new kernel and it worked
bfs patch
Applied the BFS patch
- downloaded from …
-
applied
path -p1 << bfs-patch...
secondary build
-
make the BFS-patched kernel
fakeroot make-kpkg clean fakeroot make-kpkg --initrd --append-to-version=-bfs kernel_image kernel_headers
-
install the resulting kernel
sudo dpkg -i linux-image....bfs...deb
links
History of the linux kernel
Linux test suite
CFS
Linus on CFS vs SD • http://kerneltrap.org/node/14008
Completely Fair Scheduler • http://en.wikipedia.org/wiki/Completely_Fair_Scheduler • http://kerneltrap.org/node/8059 • http://www.linuxinsight.com/files/sched-design-CFS.txt
- CFS design document
SD Scheduler • http://kerneltrap.org/SD_scheduler • http://lwn.net/Articles/231973/
- It has bound latency. CFS can't guarantee either as well as SD can. SD allows one to set the exact scheduling priority of everything and it is always respected, as there is no interactive renicing: it is very predictable.
Brain Fuck Scheduler
• http://ck.kolivas.org/patches/bfs/bfs-faq.txt
- Testing this scheduler vs CFS with the test app "forks" which forks 1000 tasks that do simple work, shows no difference in time to completion compared to CFS. That's a load of 1000 on a quad core machine.
Scheduler Benchmarking
• http://kerneltrap.org/mailarchive/linux-kernel/2007/9/17/261647 • http://lkml.org/lkml/2007/9/13/385 • http://devresources.linux-foundation.org/craiger/hackbench/
- Hackbench benchmarking program
• Testing this scheduler vs CFS with the test app "forks" which forks 1000 tasks that do simple work, shows no difference in time to completion compared to CFS. That's a load of 1000 on a quad core machine. • The 'latt' test app recently written by Jens Axboe is a better place for simpler to understand and useful numbers.
• 3D Smoothness testing
other schedulers to implement
lottery scheduler
seems nice, nice math/stat background
GA scheduler
somehow evolve different scheduling algorithms
testing suites
Scheduler Benchmarking
- http://kerneltrap.org/mailarchive/linux-kernel/2007/9/17/261647
- http://lkml.org/lkml/2007/9/13/385
- http://devresources.linux-foundation.org/craiger/hackbench/
- Testing this scheduler vs CFS with the test app "forks" which forks 1000 tasks that do simple work, shows no difference in time to completion compared to CFS. That's a load of 1000 on a quad core machine.
- The 'latt' test app recently written by Jens Axboe is a better place for simpler to understand and useful numbers.
- 3D Smoothness testing
- http://www.linuxfordevices.com/files/article027/rh-rtpaper.pdf
project tasks [1/1]
DONE project proposal
-
2-page proposal/description
-
motivation
- novel
- solving problem
- test (conventional wisdom)
- measuring
- comparing
- objective
-
background
- related work
- literature
-
methodology
- approach
- hypothesis
- validation
-
challenges
- make sure reasonable for time span
- make sure we have resources
- expected results / impact
-
motivation
- 1-3 people group
- would prefer hardcopy, but a PDF is fine
- project need not be completely defined, but should touch on potential sticking points
outline / topic
CPU scheduling http://kerneltrap.org/node/14008
Motivation - learn about kernels, proper testing environments and scheduling polices and mechanisms.
Objective - compare CFS and SD schedulers from 2007. Indentify and quantify these differences. We hope to identify these and quantify these.
Hypothesis - As indicated in the discussion between Linus Torvald and Kasper Sandberg, we expect the CFS and SD schedulers to perform better in certain niches.
Methodology - Use existing methodology and test responsiveness of throughput read pg. 704
Challenges - Setting up a valid testing and development environment. Development and testing will most likely be different (VM vs. Physical Machine). Putting together a good test suite to test different types of usage. How to evaluate performance as it's running. How does our choice in hardware affect the outcome of the results (choosing the hardware model that best)?
composition (challenges)
- Challenges
-
Setting up a valid testing and development
environment. Development and testing will most likely be
different (VM vs. Physical Machine). Putting together a good
test suite to test different types of usage. How to evaluate
performance as it's running. How does our choice in hardware
affect the outcome of the results (choosing the hardware model
that best)?
-
testing and development environment
- most likely different environments for development and for testing
- VM, kernel module, algorithmic simulation
-
test suite
- define what is meant by "interactive" use
- tailored to the particular aims of our investigation
- popular (so our results can be compared to others)
-
how to perform a "live" evaluation of the performance
- Heisenberg uncertainty principle
- impacts of hardware on results
-
resources
- hardware
- test suite
-
testing and development environment
note
Also, something to note about the history of linux schedulers is that the SD scheduler was never merged into the mainline kernel. The predecessor to CFS was the "O(1) Scheduler." The SD scheduler was more of a contemporary competitor to the CFS that lost out.
final
intro
The release of Completely Fair Scheduler in 2007 sparked significant debate on various Linux kernel mailing lists and forums. Compared to its predecessor (SD) which used run-queues, CFS utilizes a time ordered red-black tree. While CFS design implemented a “radical” shift in data structures, the benefits are not immediately visible. In several instances The SD scheduler was reported to handle 3D gaming better, providing a smoother display to the user. SD was viewed as the reference in the development for CFS yet it seems the decision to include CFS in the mainline was partially political. As Linus Torvalds was quoted, “[A] person [Ingo] who can actually be bothered to follow up on problem reports is a hell of a lot more important than one who just argues with reporters [Con]”.
Our objective is to analyze the differences between the two methods of scheduling (including patched versions) and to determine the possible benefits of using one system over the other. This implies a wide range of testing procedures in order to provide a balanced perspective on the debate. A secondary goal is to gain first hand experience with kernels, proper testing environments, scheduler policies and mechanisms.
We hypothesize that early versions of the CFS scheduler's performance does not match that of SD, but through tweaking and applied patches, CFS surpasses SD in performance.
methodology
Testing the schedulers will require modifying the Linux kernel. We will investigate modifying the kernel on two different levels:
- The first is to implement schedulers as individual kernel modules. This way is preferred as we would not have to recompile and maintain independent kernels but instead have individual scheduling modules compiled for the same kernel. We could specify which scheduler to use as a boot flag or, ideally, on the fly–if possible.
- If using kernel modules is not possible, then we will be required to compile and install independent kernels for each of the schedulers that we want to test. These will be chosen from at boot time.
The CFS scheduler is presently in the mainline kernel (true as of 2.6.13). Implementing the SD scheduler will require applying patches against the mainline kernel. If we desire to separate the schedulers into individual kernel modules, this will require adaptation of the patches.
After our schedulers are implemented and ready for testing, we will concentrate on devising effective tests and benchmarks with which to evaluate them. We will be evaluating the schedulers according to the following criteria:
- CPU utilization
- how effectively can the scheduler utilize the CPU
- Throughput
- the rate at which jobs are completed
- Turnaround time
- the time it takes to finish a job
- Waiting time
- the time a job spends in a waiting queue
- Response time
- the interval between activations on the waiting queue
We will research existing benchmarks for testing schedulers and only write our own as a last resort when no other appropriate benchmarks can be found. In addition to artificial benchmarks, we will also perform real world tests, such as listening to music when other processes are hogging the processor and benchmarking games such as Unreal Tournament 2004.
In addition to the above, we are also interesting in exploring the following optional paths:
- Testing Kolivas's Brain Fuck Scheduler (BFS)–this is a recent (August 2009) successor to the SD scheduler
- Implementing control group schedulers such as round-robin to become more comfortable with writing our own schedulers
- Experimenting with possible improvements to the schedulers, such as by tweaking parameters
challenges
There will be a number of challenges inherent in carrying out our methodology. The first being the establishment of appropriate kernel development and testing environments. Each of these environments will have different requirements
- development
- A good development environment should allow for a reasonably quick closed testing loop for new code, and should be well protected from the unpredictable and likely harmful side effects of experimental code. Given these restrictions a good development environment will likely be contained inside of a VM, or on an expendable piece of hardware.
- testing
- A good testing environment should resemble as closely as possible the actual production environment of the kernel. For this reason we will probably test directly on a physical machine, rather than through a virtual machine. If a wider variety of hardware is desirable than is available some sort of "simulated" test environment may be required. such a simulated scheduling environment would allow more flexibility in varying simulated hardware components and the related performance determining constants, but may yield less veracious results.
Once we have established an acceptable development and testing framework the next challenge will be the acquisition of a suitable testing suite. Two issues related to the availability of a test suite are the possibly prohibitive cost of high quality "standard" test suites and the potential lack of any widely accepted test suites directed at the particular aims of our study (specifically scheduler performance over different "types" of load including interactive use and batch use).
Some tradeoff will have to be made between the amount of information returned by a test suite $Δ P$, and the suites impact on the load $Δ L$ on the system. A situation similar to the Heisenberg uncertainty principle is expected where increasing the precision of our knowledge of the system at any point decreases the our knowledge of the load such that the two are only knowable up to some hardware constant $\hbar$.
$$ Δ P × Δ L \geq \frac{\hbar}{ 2 } $$
If this tradeoff proves untenable then we may be required to resort to a simulated test environment, or a scheme of partitioning the running system inside of a virtual machine and collecting our metrics from outside of the machine.
implementation
- kernel
- 2.6.31 (this is what the current BFS patch is against)
exams [1/3]
TODO final exam
in classroom
TODO final review
in CS141
DONE midterm
-
format
- questions like the reading response questions
- essay questions
-
topics
- kernel design
- memory management
- virtualization
- test general OS concepts
-
care less about specifics, and more about the effects of the mechanisms
- not how did x solve y, rather, how could one solve y
topics
OS structure
- standard monolithic
-
entire OS is in kernel space
- pros
- faster (less context switching)
- cons
-
- complexity, size
- less flexible/extensible can't customize w/o changing kernel space code
- harder to move to new hardware
- less secure/stable (more low-level components to keep track of)
- µ-kernel
-
only supports basic structures (l4 address spaces,
threads, scheduling, and IPC) and pushes rest of the OS out into
user-space servers
- pros
-
- simpler
- easier to move to new hardware
- flexible
- more secure/reliable because of the simplicity of the low-level interface
- cons
-
- slower
- exokernel
-
only does multiplexing of HW resources, rest of OS is
in users pace libraries. end-to-end argument: application knows
best how to handle it's own resources.
- pros
-
- direct access to hardware
- flexible
- cons
-
- no security gains like in µ-kernel
- cooperation
- virtualization structures
-
as example of general system management
structure
- fault containment
- porting old OS to new hardware
- slower
understand
-
implication of these structures to the performance of the OS
- micro-benchmarks
- macro-benchmarks (applications)
- implication for extensibility of the OS
- separation of protection of resources, mechanisms, policy
processes and threads
- address spaces
- virtual memory of a process
- process state
- multi/batch/time-sharing programming
-
- multi-programming
- multiple tasks, can be single user
- time-sharing
- multiple tasks, normally multiple users
- batch
- space sharing rather than time sharing, but the CPU is generally only given to one task at a time. queue of processes
- context switch
- swap
models of communication
- message passing
- shared memory (on different architectures NUMA, UMA, etc…)
synchronization
- monitors
- software constructs surrounding critical sections
- semaphores (less)
- counting or binary, primitive locks, counting counts how many people can be in critical section simultaneously, decrements as each individual enters the critical section
- mutex
- simple binary semaphore (potentially has additional features protecting against priority-inversion)
- critical section
- section of code which is run inside of a lock, semaphore etc…
- deadlock
- (see deadlock)
- condition variables, their semantics
- used for IPC, avoid spinning.
Models (see notes above)
- kernel threads
- user threads
- hybridization
- scheduler activations paper
process scheduling
- metrics to consider
-
responsiveness (time from submission to first
response), submission to completion, wait time (sum of the time
spent on the ready queue), throughput (job completion in a
chunk), turnaround (form start to finish)
- user-centric
- response, wait, turnaround
- system-centric
- throughput, utilization
- preemptive v.s. non-preemptive
- can't knock a process off of the CPU until the process yields
- fair scheduling
- CPU is equally distributed between users or groups rather than among processes
memory management
- working set
- set of pages needed while running
- thrashing
- when the working set doesn't fit in memory, when the OS spends more time paging then executing
- allocating memory (contiguous vs. non-contiguous)
- contiguous maps the address space directly to disk through a base and offset, non-contiguous (like paging) allows individual pages to be loaded w/o loading the entire address space at once.
- address space protection
- gained through paging or segmentation
- segmentation
-
like in the Multics paper
- variable length
- semantics (program or data)
- permissions like on files
- potentially with a directory structure
- paging
-
allocation, selection, levels of caches, replacement
- fixed size
- less semantics than segments
- mapping pages to disk
- page faults are resolved as high up the cache hierarchy as possible
- LRU, stuff like that
- copy-on-write
- p.325 Dinosaur book
- memory-mapped IO
-
map a section of memory to a place on disk, and
all you have to do is write to memory. copies part of disk to ram
- this requires explicit handling in the user-level application. initial system call to set it up (open/close)
- faster, only have to write to memory (and it will later be written to the mapped portion of the disk)
- there is an explicit system call to sync to disk
- might be asynchronous
- slower for changes to propagate to disk
miscellaneous
- reliability
-
scalability (clients, processors, resources, etc…)
- weak scaling
- increase workload as increase resources (constant time)
- strong scaling
- decrease time as increase resources (constant workload)
question
difference between grafting and co-location?
or between co-location and threads
how can secure binding ensure good behavior after binding?
concepts / terms
MIPS
http://en.wikipedia.org/wiki/Search?search=MIPSarchitecture
originally stood for "Microprocessor without Interlocked Pipeline Stages"
it is a RISC instruction set architecture.
interrupts
p.499 in dinosaur