To cover several assembler directives and assembler expressions provided by the GNU assembler (gas) and the SPARC addressing modes.
After completing this lab, you will be able to write assembly language programs that use:
In this lab we introduce three new assembler directives: a directive to allocate space, a directive to define symbolic constants, and a directive to include header files. After we describing these directives, we discuss assembler expressions and introduce the distinction between relocatable values and absolute values. We conclude this lab by discussing the memory addressing modes provided by the SPARC and the SETHI instruction.
In Lab 2 we introduced three assembler directives: .data, .text, and .word. In this Lab, we introduce three more directives: .skip, .set, and .include. The .skip directive is used to allocate space. The .set directive is used to define a symbolic constant. The .include directive is used to include source (header) files.
You can use the .skip directive to allocate space in the current assembler segment (data or text). This directive takes one or two arguments. The first argument specifies the number of bytes to skip in the current assembler segment. The second argument specifies the value to be deposited in the skipped bytes. If the second argument is omitted, it is assumed to be zero.
You can define symbolic constants using the .set directive. This directive takes two arguments. The first argument is the name of the symbol to be defined. The second argument is an expression that defines the value of the symbol. This directive can be written using standard directive syntax (e.g., .set symbol, expression), or it can be written using the infix `=' operator (e.g., symbol = expression).
In many cases, you will want to collect a group of definitions for symbolic constants into a header file that can be included in several different programs or modules. (By including the same file in each of the programs or modules, you can be sure that all of the programs and modules use the same values for the symbolic constants.) The .include directive supports this style of programming. This directive takes a single argument, a string that gives the name of the file to include. The code from the included file logically replaces the .include directive. When the assembler is finished processing the included file, it resumes after the .include directive in the original file.
Table 6.1 summarizes the directives that we have introduced in this section.
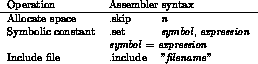
Table 6.1: Assembler directives
The .set and .skip directives use assembler expressions. In addition, you can use assembler expressions whenever you use a constant value in an assembly language instruction. Table 6.2 summarizes the operators that you can use constructing expressions. The operands can be expressions (using parentheses to override precedence), symbols (defined as labels or using the .set directive), or numbers.
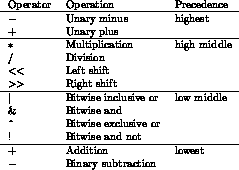
Table 6.2: Assembler expressions
When considering assembler expressions, it is useful to distinguish between relocatable values and absolute values. Labels are the simplest examples of relocatable values. They are relocatable because their final values depend on where your program is loaded into memory. Numbers are the simplest examples of absolute values. Absolute values do not depend on where your program is loaded into memory.
You can use absolute values with any of the operators. If all of the operands for an operator are absolute values, the expression using the operator is an absolute value.
You can only use relocatable values in expressions using the binary addition and subtraction operators. When you use binary addition, at most one operand can be a relocatable value, the other operand must be an absolute value. If one operand is relocatable, the value of the expression is relocatable.
When you use binary subtraction, you cannot subtract a relocatable value from an absolute value. When subtract an absolute value from a relocatable value, the result is a relocatable value. When you subtract two relocatable values, the two values must be defined in the same assembler segment (e.g., text or data), and the result is an absolute value.
The SPARC supports two addressing modes: register indirect with index and register indirect with displacement. In the first mode, the effective address is calculated by adding the contents two integer registers. This addressing mode is commonly used to access an array element: one of the registers holds the base address of the array, the other holds the (scaled) index of the element.
In the second mode, the effective address is calculated by adding a 13-bit signed integer constant to a register. This addressing mode can be used with pointers to structures: the register holds the address of the structure and the integer constant specifies the offset of the member (field) being accessed. Register indirect with displacement addressing is also commonly used when accessing items on the runtime stack (e.g., parameters and local variables). We consider access to the runtime stack in Lab 12 when we consider standard procedure calling conventions for the SPARC.
Table 6.3 summarizes the addressing modes supported by SPARC assemblers. In addition to the two basic addressing modes, SPARC assemblers recognize register indirect addressing and a limited form of direct memory addressing. Direct memory addresses are limited to values that can be expressed in 13-bits when sign-extended (i.e., very small addresses and very large addresses).

Table 6.3: Assembler address specifications
Addressing modes can only be used with the load and store instructions. Table 6.4 summarizes the load word and store word operations.

Table 6.4: The SPARC ld and st operations
We conclude this discussion by introducing another SPARC instruction, sethi, and the %hi and %lo operators provided by SPARC assemblers. The sethi instruction takes two arguments: a 22-bit constant and a destination register. This instruction sets the most significant 22 bits of the destination register and clears the least significant 10 bits of this register.
.set bignum, 0x87654321
sethi bignum>>10, %r2
or %r2, bignum&0x3ff, %r2
ta 0
Note the use of the expression ``bignum>>10'' to extract the most significant 22 bits of bignum and the expression ``bignum&0x3ff'' to extract the least significant 10 bits of bignum. To make your code more readable, SPARC assemblers provide two special operators: %hi(x) yields the most significant 22 bits of x, while %lo(x) yields the least significant 10 bits of x. Note that these operators are written using function call notation.
.set bignum, 0x87654321
sethi %hi(bignum), %r2
or %r2, %lo(bignum), %r2
ta 0
.data
arr: .skip 20*4 ! allocate an array of 20 words
sum: .word 0 ! allocate a word to hold the sum
.text
start: set arr, %r2 ! %r2 is the base address
mov %r0, %r3 ! %r3 is the index value
mov %r0, %r4 ! %r4 is the running sum
set 20, %r5 ! %r5 is the number of elems to add
loop: ld [%r2+%r3], %r6 ! fetch the next element
add %r4, %r6, %r4 ! add it to the running sum
subcc %r5, 1, %r5 ! one fewer element
bne loop ! if %r5 > 0 get next element
add %r3, 4, %r3 ! increment the index (DELAY SLOT)
sethi %hi(sum), %r1 ! store the result in sum
st %r4, [%r1+%lo(sum)]
end: ta 0
Note that the code in Example 6.3 stores the result into sum using a sethi instruction followed by a st instruction. In previous examples we have used a set instruction followed by a st instruction to accomplish the same task. However, the set instruction is actually a synthetic instruction and the assembler implements this instruction using a sethi instruction followed by an or instruction (as we showed in Example 6.1). As such, our earlier code actually requires three instruction for every (load or) store. Using the sethi instruction directly, we can avoid an unnecessary instruction.