Robotic Task Learning
Faculty MembersDr. Lydia TapiaPostdocsDr. Satomi SugayaGrad StudentsTorin AdamsonJohn Baxter Mohammad R. Yousefi AlumniDr. Nick MaloneDr. Aleksandra Faust CollaboratorsDr. Andrew R. FerdinandDr. John Wood Dr. Brandon Rohrer Dr. Ron Lumia Related ProjectsAdaptive Quadrotor Control |

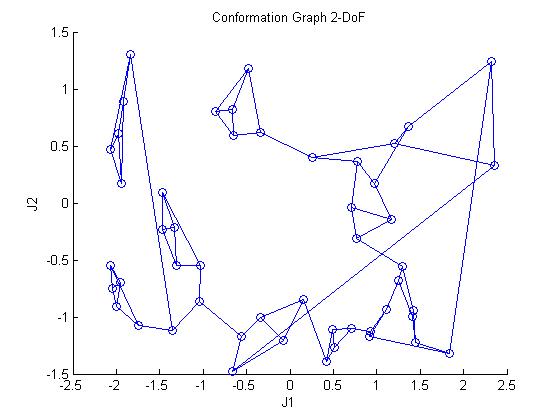
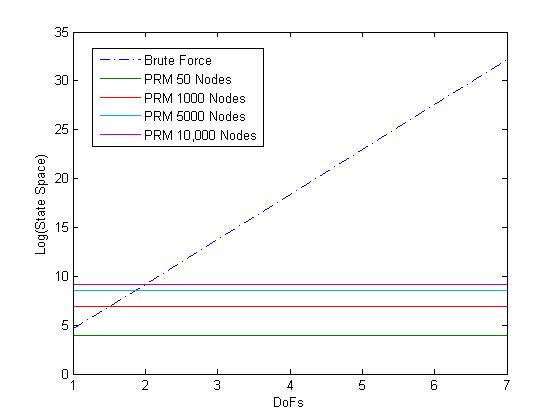
Robotic task learning is a challenging and emerging area of research. Tasks are any discrete goal which a robot must accomplish. However, it is not yet clear how to consistently teach a robot how to perform even the simplest tasks which a human child can perform with ease. The canonical task: "Bring me that glass of water" is beyond the capabilities of the most advanced learning algorithms. Robotic learning uses a wide variety of machine learning techniques ranging from reinforcement learning to demonstration learning. Our research is focused on reinforcement learning (RL) and ways in which to optimize the convergence time of RL algorithms. Reinforcement Learning is a special area of machine learning that is focused on maximizing rewards obtained by the agent. We utilize a RL package called BECCA (https://github.com/brohrer/becca), which was developed by Brandon Rohrer, previously at Sandia National Laboratories.  Block Diagram of the component of BECCA BECCA is a general reinforcement learning agent tied to a feature creator. The learning agent keeps a model of cause-effect pairs and choses the next action based on matching the current working memory to the cause-effect pairs. The working memory is simply a short history of previous observations and actions. The feature creator builds up groups of related inputs and sends these inputs to the reinforcement learner. More about BECCA can be learned at Brandon's website here (http://brohrer.github.io/). Reinforcement Learning struggles with large state spaces, so we have combined Reinforcement Learning with Probabilistic Roadmap Methods (PRMs). PRMs sample configurations in the environment and then connect configurations in a neighborhood to form a roadmap. This roadmap provides an approximated model of state space. The size of the state space is one of the largest factors in convergence time of a Reinforcement Learning algorithm, and thus the approximated model provided by the PRM aids greatly in this regard.
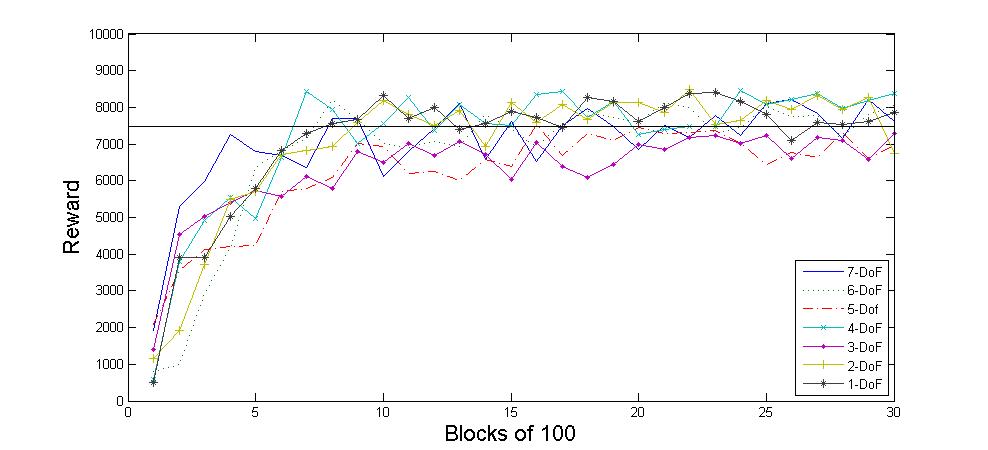
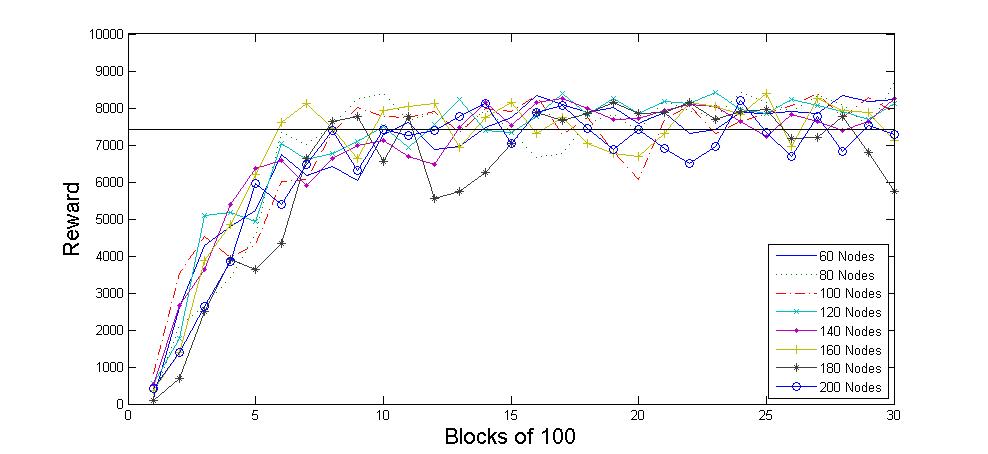
Using this PRM-BECCA learning scheme we can have BECCA learn to navigate a 7DoF WAM robot in pointing tasks. The interesting change this has on the problem is that the learning algorithm is largely agnostic to the DoFs and the number of nodes in the roadmap, in terms of iterations required to converge. However, increasing the number of nodes in the roadmap does increase the time it takes to process each iteration. This means that the learning algorithm is bounded by the roadmap size needed to solve a particular problem instead of by the complexity of the robot.
VideosBECCA Pointing Task on a WAMPublications & Papers(pdf, BibTex, abstract, presentation) (pdf, BibTex, abstract, presentation) |