|
Donour Sizemore (donour@uchicago.edu)
Computing is an important tool for the scientific researcher. The document attempts to briefly describe the computing resources available to members of the Economics Research Center at the University of Chicago. It also provides brief tutorial for the numerous tools and systems available to researchers. This guide is intended for to help memebers of the ERC perform their research easier and more efficiently.
This document is intended also to be a short guide to good scientific programming. A large portion is devoted to the tools and techniques necessary for numerical computing. High performance computing is emphasized, but some regard is given to the workstation numerical computing applications (matlab, stata, mathematica).
A third focus is the introduction of elementary concepts in computer systems and software engineering. I give particulary atttention to Unix tool chains, as many users may be unfamiliar with the environment.
Questions and corrections should be directed to the author and additions are always welcome.
Several computing platforms are available to the researchers in the ERC. The three most prevalent are Unix, Windows, Macintosh. The high-performance compute servers all run Unix, while most of the desktop machines are Windows or Mac. A strong preference is given to doing numerically intensive work on Unix.
Large computations should be performed on one of our Unix2.1servers. They offer a 64bit address space and considerably more memory than a desktop. The Unix servers will also be more reliable for long running jobs and in most cases will provide higher floating point performance. Several servers are available.
|
The home directories on Athens sit on a large fibre channel raid. This filesystem is reliable and should be the primary location to store files. Altus and Vanguard provide large local scratch space for jobs that need it.As always however, users should manually backup important data.
NSIT maintains a few Unix tutorials at http://support.uchicago.edu/docs/unix.
Every graduate student has access to the Window workstations in the SRC Economics Lab (room 016 : 1155 E. 60th St.) These workstations allow access to an array of standard statistical and scientific computing packages. Students can also log into the Unix servers from here.
Windows has much better content creation tools (Word processors, slideshow editors, etc.) than Unix and most users prefer this platform for their day to day computing.
Researchers with a valid CnetID can register an account at http://athens.src.uchicago.edu/econlab/newacct.shtml.
To be completed...
Cygwin is an environment that will allow you to run most Unix tools under Windows. It supports on all recent (Win95 and higher) releases of Windows. Using Cygwin, you get access to:
After installing cygwin, you can launch a shell that behaves very much like Unix terminal. From this shell, it is much easier to inteact with remote Unix systems. In addition Cygwin provides a POSIX2.2 API so that most Unix applications can run on windows relatively unmodified.
Cygwin is available for free at the cygwin website: http://www.cygwin.com.
To be completed...
All desktop PCs and Unix servers have a recent release of Matlab installed.
Profiling allows you to see which parts of a matlab program take the most time. You can then target these sections when tuning performance.
>> profile on > profile clear
These commands turns on Matlab's profiler. The profiler will gather statistics about the running time of all the functions you call. After turning on the profiler, run your matlab job as you would normally. After your program completes, run the following command to generate a report.
>> profile report performance_report.html
This generates an HTML file named performance_report.html which contains the performance breakdown of the various functions called during the profiling session.
Scilab is a free alternative to Matlab.
To be completed.
To be completed...
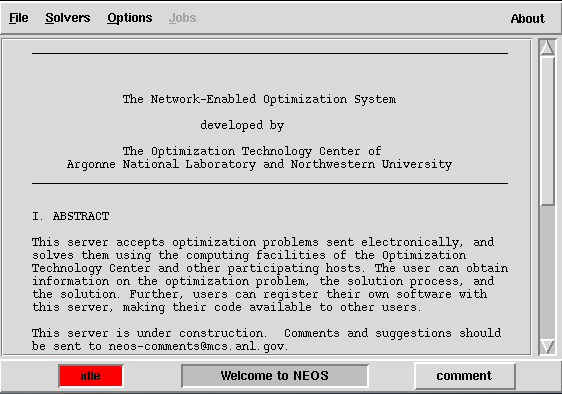
The Network-Enabled Optimization Server (Neos) is a collection of optimization solvers provided by Argonne National Labratory and Northwestern University. Solvers are available for a variety of methods including Linear Programming, Integer Programming, and Global Optimization. Neos allows the user to formulate their optimization problem using one of several standard formats, then submit it remotely for processing. No special accounts or software licenses are necessary.
Consider the example in table 3.1 from A Gams Tutorial
[11] by Richard Rosenthal.
client-2.0
client-2.0/bin
client-2.0/bin/install.pl
client-2.0/bin/client.pl
client-2.0/bin/comms
client-2.0/bin/comms-daemon
client-2.0/bin/submit
client-2.0/lib
client-2.0/lib/icon.bmp
client-2.0/Makefile
client-2.0/README
client-2.0/Tutorial.pdf
client-2.0/ex
The file submit in the bin/ directory is the job
submitting perl script. When run, it will present the user with main
job submission screen (Fig. 3.4).
Using the Solvers menu, then selecting Linear Programming,
then GAMS, one can submit the Gams example from table
3.1. After submitting the job, the Neos system executes the
solver on a backend server without and intervention from the user. A
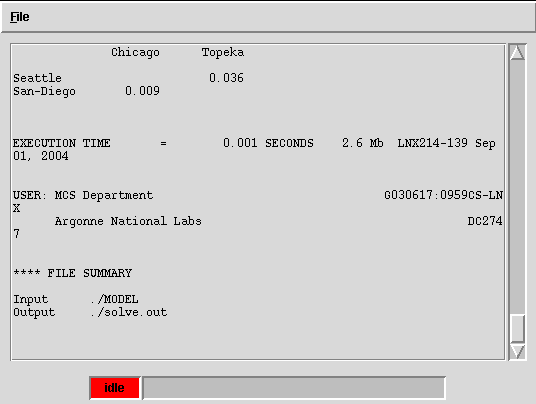
job output box, similiar to the one in fig. 3.4,
should appear with the results.
Further documentation is available at the official Neos website:
http://www-neos.mcs.anl.gov.
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
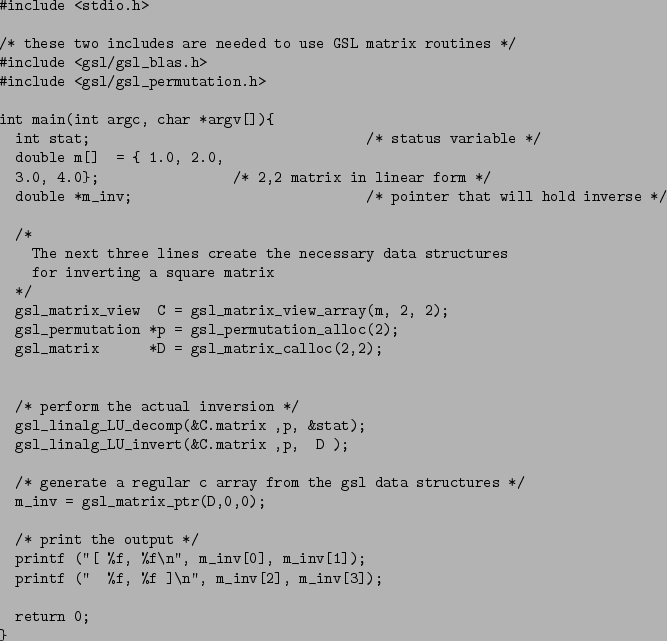
The GNU Scientific Library (GSL) is a free implementation of a variety of numberical and scientific routines. The library is written in C, and is consequently very portable. In addition to C, wrappers are available to use the library with C++, Perl, Python, Ruby, and OCAML. The GSL provides a C implementation of netlibs Basic Linear Algebra Subprogrms (BLAS). BLAS allows users to manipulate vectors and matrices easily. It also provides random number generators with uniform, normal, log-normal, and Poisson distributions.
Full documentation is available in the GSL manual[10].
A compiler is a program that translates code from a source language to another. In the vast majority of cases, compilers translate code from a human-readable high level language to a machine code.
Most compilers use a variety of techniques to optimize code for speed and size.
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
To be completed...
Make is a tool to automate program building3.1. For most programs, Make greatly simplifies the task of repeated building a program and changing the build options.
Make uses a file named Makefile to determine how to build a program. Almost all errors associated with Make are due to incorrect makefiles. To make matters worse, Make is very sensitive to the formatting of text in makefiles. Typical makefile consists of two things:
These usually consists only of source files. The file names can be stored in variables in the makefile. Variables in makefiles are similiar to Unix environment variables. For example:
SRCS = source1.c source2.c source3.c
The variable SRCS now contains the three source files, source1.c,source2.c, source3.c. For the rest of the
makefile, you can use $(SRCS) instead of the three source
files explicitly.
You will need to specify what compiler, linkers, and options are used to build the program. This information can also be store in variables as well.
CC = gcc
CFLAGS = -O3 -lm
This configures $(CC) to be the c compiler gcc and
$(CFLAGS) turns on performance optimization and links with
the math library.
Make allows you to define rules, that specify what actions are performed when Make is invoked. Rules have the following form:
target: dependencies
commands ...
The target specifies what program, or part of program, is being built. Examples of targets might be debug for linking in debugging information of a program or obj for just building objects from the source code.
The dependencies are a list of targets that must be built before building the current target. Using the previous example, you cannot link in debugging information until you've built the source objects.
The commands are simply a list of commands, one per line, that build the target.
$(CC) $(CFLAGS) $(SRCS) -o prog $
This command will use the c compiler, the c flags, and the sources defined earlier to build a program named prog.
IMPORTANT: Note that each command must be shifted to the right one TAB character and that a TAB character is not the same as a number of spaces. If you try to use spaces instead of the TAB character, make will not accept the makefile
Putting this all together, lets look at a full makefile3.2:
Notice that there are three targets defined: release, debug, and clean. Those familiar with GCC should see that release builds a standard, optimized executable, while debug inserts standard gdb debug information. clean will remove old object files and the executables from earlier builds.
To build the program, simply run Make with the target as a option. If no target is specified, the first target in the makefile is selected.
[donour@host]~examples/make$ make debug $ gcc -O3 -lm main.c -g -o debug [donour@host]~examples/make$$
Now, notice what happens if we try to run the same command again.
[donour@host]~examples/make$ make debug $ make: `debug' is up to date. [donour@host]~examples/make$$
An important feature of Make is that it does not try to recompile files that have not changed. Large projects, with many files, build much quicker if only changed files need to be processed.
There are many versions of Make available. The most popular is GNU Make[3]. However, many commercial Unix vendors provide their own Make implementation. On Solaris, Sun Make is set as the default make program, although GNU Make is available as well.
While all Make implementations do not behave identically, they each adhere to a standard that gaurantees that fairly simple makefiles (as used in this guide) will work on all versions. Version specific features are covered in the Advanced Features section.
-implicit rules -version specific features
To be completed...
To be completed...
To be completed...
A large body of research is concerned with how to write programs easily and efficiently. Programmers want their code to be simple, clear, and easy to modify. They want to be able to come back to a codebase, long after working on it, and be able to modify or add to it with minimal effort. All software will require maintenance and often times finding a single bug will require major reworking of a programs architecture. Scientific programming imposes the additional requirement that results be reproducable and that code be readable enough for peer review.
The only way to really learn how to program is to write programs.
Peer review is a very important step of producing correct scientific results. In the early stage of developement, an extra set of eyes will help find bugs quicker and provide insight into how to make your code clear.
One of the most important ideas to emerge from early software engineering work is the method of structured programming. Structured programming consists of writing code using flow control with well-defined entry and exit points5.1. The ``if-then-else'', ``for'', and ``while'' constructs are the most often seen examples in procedural programming languages.
Good structure greatly increases a program's readability and makes it easier to improve performance, or add features to a program later on. It also makes it much easier for a new users to read and understand the program.
Programmers usually break a program into smaller more manageable parts that can be easily written, modified, and debugged. A logical extension of structured programming is code modularity. Most programming languages now provide a away to abstract functionality into parts that can be loaded as needed. Fortran90 provides the module and use primitives. C++ provides classes and namespaces. Indeed every modern language provides some way to modularize programs.
It is generally a good idea to modularize programs as much as possible in order to produce clear and correct code. Remember that no matter how fast a routine runs, it's results are useless if incorrect.
Comments are docmentation, provided inline with the program, that explain what a programing is doing or clarifies confusing bits of code. They are ignored by the compiler and interpreter and do not affect program execution.
People often ask to what extent they should comment their code. The general rule of thumb is to explain any bit of code that was confusing to write or counters intuition. Do not simply restate what a piece of code is doing. Effective comments supplement the code in explaining program behavior. Consider:
while ( i < 5){
i = i + 1; /* add 1 to i */
}
This is not a useful comment because it is superfluous.
/* calculate factorial of n: (n*n-1*...*2*1) */
int fact(int n){
if( n <= 1)
return 1;
return n * fact(n-1)
}
This is better because it captures what the programmer is trying to do
with a self contained piece of code.
In scientific computing, it is also useful to have a short paragraph at the beginning of every program that explains what is being calculated and gives references to background literature and the author. If a piece of code is suceptible to floating point error that should be noted, as should any problem that might lead to incorrect results.
Optimize variable names for maximum clarity, not minimum typing. - Krzysztof Kowalczyk
Although it may seem insignificant, it is important to pick variables names that correspond to some value in the original problem or some action in the program. That being said; i, j, tmp are perfectly legitimate choices for variable names. Indeed i has been used denote looping in mathematics for quite some time. However, having 20 single character variables in scope at a time will be confusing and leads to arithmetic expressions which are very hard to read and correct.
In line with the notion of modulization, it is important to test code as it's written. Again, it's easier to test and reason about a small bits of code. It's always better to stop and correct mistakes early, rather than have to wade back through working code to find an error.
Source management software allows programmers to maintain different versions of programs as they are developed. The software makes it easy to track changes in programs and incorporate bugfixes or new features than may be contributed by others. In particular, source management becomes vital when more than one person is working on a project at a time. It is time consuming and complex to integrate changes when several people are working on the same project simultaneously. Source management tools can do this automatically.
It is strongly advised that all programming projects use source management. The Concurrent Versions System (cvs) is widely used in academia. All of our Unix machines have a version of CVS installed. WinCVS is available for free on Windows. CVS documentation is available online and in the manual [6];
Other version control systems include:
Users are encouraged to work with whatever system they feel is most comfortable.
TODO: create and document central code repository
FIXME - cvs repository creation example
Tip: $Revision: 1.25 $, $Date: 2004/09/29 15:18:10 $ tags
Debugging tutorials usually discourage the use of print statements to verify correct calculations because they seem cumbersome and uninformative. On the contrary, a few print statements can be inserted into broken code very quicky and will often reveal where bugs originate.
On the otherhand, using a sophisticated debugging tool will often save a tremendous amount of time and frustration. Several such tools exist for Unix.
The GNU debugger,GDB,is avilable on all Unix machines. Documentation on GDB can be found at http://sources.redhat.com/gdb/documentation. A number of front ends exist for GDB. Most notable are the Data Display Debugger (DDD) and emacs integration.
To use gdb effectively, have the compiler insert debugging information into the executable. Note that debugging information increases code size and makes a program run somewhat slower. Some compilers do not allow the debugging and optimization flags to be specified simultaneously. The ones that do, such as gcc make no guarantees that the resulting program is actually debug-able. Optimization often reorders instructions, moves operations out of loops, and sometimes removes instructions altogether.
|
Consider the following buggy C program:
int main(int argc, char *argv[])
{
double data[2] = {2.71828,1.6180};
data[9999] = 3.141;
return 0;
}
This programs segfaults when you try to run it. Lets use gdb to
determine where and why it segfaults5.2.
$ gcc -g example.c -o example
$ gdb example
(gdb) run
Program received signal SIGSEGV, Segmentation fault. 0x0804835c in main (argc=1, argv=0xbfffe104) at example.c:4 4 data[9999] = 3.141;
In many cases, knowing which line is causing the crash will reveal the bug immediately. Here, we know that an assignment is causing the undesired behavior. The right-hand side is a constant, so it can't be causing the problem. Therefore data[9999] must be invalid. Lets verify.
(gdb) print data
1 = {2.71828, 1.6180000000000001}
We see that data, as declared in the beginning of our program is an array of length two. There is no 9999th element. We can verify that as well.
(gdb) print data[9999] Cannot access memory at address 0xc0011918
This method can be used to find bugs in much more complex programs. GDB will let the user single step through instructions, modify variable values, and even call functions from a suspended program.
To be completed...
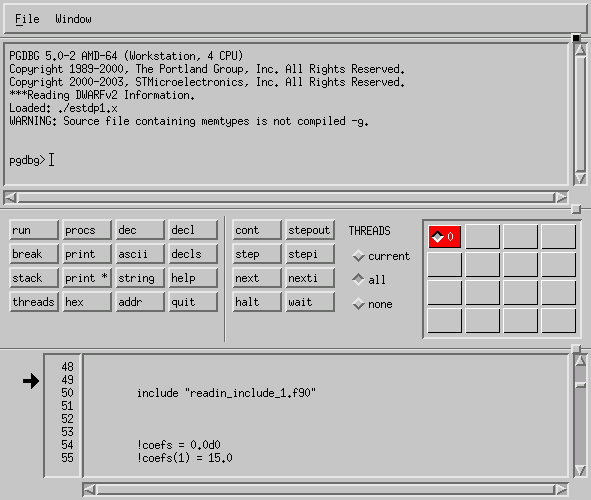
pgdbg is the debugger provide with PGI's Fortran
compiler. Unlike gdb it provides a graphical interface for the
user. To start pgdbg, run:
$ pgdbg estdp1.x
This starts a debug session on the program estdp1.x and brings up the main window.
From here, you can monitor your program (set break points, view disassembly, get stack traces, etc.). pgdbg provides a windows to view the original source and I/O from the program.
pgdbg provides much better support parallel programs than gdb. It will allow you to debug threaded programs on a single machine or MPI programs which distribute calculations across many systems[7]. This is useful because debugging parallel programs is significantly harder than serial ones.
Large simulations may require high-performance, hand written code. Users will likely wish to parallelize their code using compiler loop decomposition or explicit programming directives. Help with writing threaded or messaging passing programs is available.
Before attempting to make a program faster, you will want to know which parts are slow and why. Some tools are available to collect quantitative data on the performance of programs.
This command prints the execution time of a program. It is useful when making changes that affect the speed of an entire program (such as running with 2 vs. 4 CPUs).
For most programs, the majority of of execution time is spent in a very small part of the code6.1. The first job of performance analysis is to locate these crucial segements and determine a way to make them faster.
Most compilers can insert measurement code, that reports the time spent in each routine, into a program. Refer to table FIXME[profile flags] for the relevant flags. After compiling with profiling support, run your code until completion. When it terminates, profile data and a call graph will be written to disk. Now a program is needed to make sense of this data.
|
FIXME: insert profiling example
-timeslices
Tip: buffer I/O operations
Only the operating system (OS) can actually interact with a computer's hardware. Everytime a program wants to perform an I/O operation (such as printing to the screen), it must relinquish control of the CPU to the OS.
It's commonly believed that increasing a process' priority very high or using real-time scheduling somehow makes the code go faster. In fact, setting the priority too high often results in worse performance because additional checks must be performed by the operating system to insure operations experience low latency.
- precompute if possible
- refactor subexpressions
- loop unrolling
To be completed...
All Unix machines have the free Fortran 77 compiler, g77. Although some Windows workstations have licenses for Compaq's Visual Fortran studio, it is strongly advised that users run their fortran code on Unix.
Sun servers also include the commercial Sun Fortran 90/95 compiler.
All Unix machines have the free C and C++ compiler, gcc. Sun servers include the commercial Sun C compiler.
It is suggested that programmers use gcc, version 3.2 or greater.
Bash stands for the Borne Again SHell. It is the default shell for our Unix systems.
When Bash is involked is reads a series of configuration files. Bash will interpret each line of these files as a comand, therefore they are the natural place for setup your environment or run commands automatically when you log on. In order, bash reads the following files:
-i/o redirection.
Bash is a powerful tool and advanced users would do well to read the manual[4].
Parallel Programming is the process of writing programs so that more than one task can be performed simultaneously. The goal is either concurrency, performance gain, or both. In the case of the former, the programmer may wish for some work to be done while waiting on another task to complete (e.g. write a file to disk, or wait for data on the network). This method can also be employed to make programs seem interactive. Interactively is rarely of interest in scientific computer, so we move on to the other goal. The second motivation, of course, is to make programs run faster by taking advantage of several CPUs simultaneously. Often, a computation can be split into smaller parts that can be calculated independently and then reassembled to produce the final answer. Therefore, writing a parallel programs involves:
Suppose a problem requires the sum of the first N natural numbers8.1 and has four processors available. For convenience, lets define the function sum.
procedure sum(start, end)
total := 0
for i=start,end
total = total + i
return total
The answer can be computed serially as follows:
sum(1,N)
Now we observe that each addition operation is independent, so can distribute
the calculation uniformly across our for processors. Each CPU can calculate the
partial sum ![]() numbers and the we can add these results together to
get the full sum. A parallel version might look like:
numbers and the we can add these results together to
get the full sum. A parallel version might look like:
sum1 = worker1::sum(1 ,N/4)
sum2 = worker2::sum(N/4+1 ,2*N/4)
sum3 = worker3::sum(2*N/4+1,3*N/4)
sum4 = worker4::sum(3*N/4+1,N)
total := sum1 + sum2 + sum3 + sum4
where worker1 computes the sum of the numbers 1 to There are two basic models used for parallel programming.
One of the most important features of parallel performance analysis is Amdahl's Law.
To be completed...
The OpenMP Application Program Interface (API) supports multi-platform shared-memory parallel programming in C/C++ and Fortran on all architectures, including Unix platforms and Windows NT platforms. Jointly defined by a group of major computer hardware and software vendors, OpenMP is a portable, scalable model that gives shared-memory parallel programmers a simple and flexible interface for developing parallel applications for platforms ranging from the desktop to the supercomputer. - www.openmp.org
OpenMP provides an easy (platform independent) way to automate the generation of code for shared memory machines. Currently, OpenMP language extentions are provided by the Sun C/Fortran compilers on athens.src.uchicago.edu and by the Portland Group HPF compilers on altus.spc.uchicago.edu and vangaurd.spc.uchicago.edu.
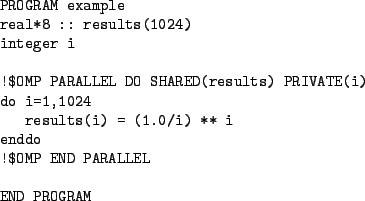
The OpenMP directives allow the programmer to explicitly specify which segments of code should be executed in parallel, but not have to deal with low level threading primitives or synchronization. Consider the following simple fortran program:
Notice the special directives (called sentials),!$OMP, which have been inserted as comments. These lines instruct the compiler to add code for parallel processing. The SHARED and PRIVATE directives tell the compiler that certain variables should be shared by all the workers or private to each individual worker8.3. Compilers that do not support the OpenMP language extensions will treat them as normal comments (ignore them). The build this program on solaris, using the SunONE compilers, run:
f90 -openmp -parallel -O omp_example.f -o example
The -openmp and -parallel flags turn on OpenMP support. Using the PGI compilers on AMD64, run:
pgf90 -mp omp_example.f -o example
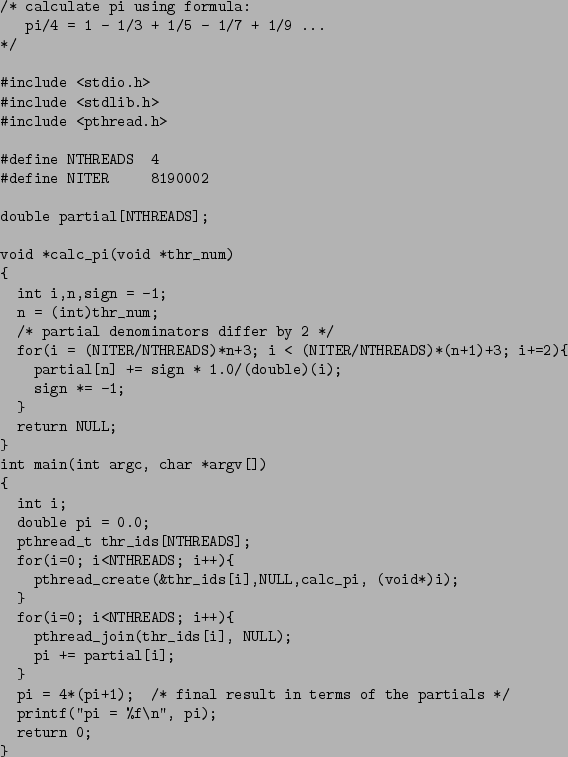
Posix Threads (PThreads) is a platform independent API for threaded programming. PThreads is available on Linux, Solaris, and Win32 and is built on top of each platforms native threading architecture.
TODO: Add pthread example
To be completed...
An alternate strategy for parallel programming is to have each task run in a seperate processes on different CPUs (or different machines) and have them communicated by passing messages back in forth. Naturally the programmer does not want to write different code for each packet of work that must be done. It would not be possible to easily repartition the calculations or dynamically add or remove CPUs from the job.
MPI[9] is an API (Application Program Interface) for writing programs that pass messages back and forth. It allows programmers to write a single piece of code that can be executed simultaneously in many places, with each piece performing a different part of the calculation. With MPI, programmers have a single interface to pass messages and do not have to worry about what types of interprocess communication are available on their particular platform,.
MPI is only an interface standard. An implementation must be available before any real work can be done. A number of implementations exists. One of the more popular is the MPIch project which is available from Argonne National Laboratory. MPIch is free and can be found at: http://www-unix.mcs.anl.gov/mpi/mpich/. MPIch supports writing programs in C, Fortran 77, and Fortran 90.
MPIch contains two parts that the user will be most concerned with: the library which must be linked with the application program and scripts used to build and run mpi programs.
Consider the following C example which approximates ![]() using the
infinite series,
using the
infinite series,
![]() :
:
[donour@host]~/$ mpicc example.c -o example $
[donour@host]~/mpi$ mpirun -np 1 ./example pi = 3.141592655451890 [donour@host]~/mpi$
The argument -np 1 instructs mpirun to only start one process. Thus only one CPU is used. To run the job on more CPUs, simply change the argument. mpirun -np 8 ./example will run the job on 8 CPUs.
mpirun requires some variant of the Remote Shell (rsh) to log into remote machines and start each process. In almost all cases, this should be SSH. You will also not want to have to type the password for each machine. To find out how to alleviate this problem refer to the SSH key section in A.1.1.
By the very nature of MPI, you must copy the program you want to each machine that will run it. mpirun also requires that every machine involved in the job have the program in same location on the filesystem. More precisely, the program must have the same absolute path8.4 on each node. On many systems this is accomplished by sharing users home directories over the network8.5. That way, a programs,data, and changes are available to all machines automatically.
MPIch can allows you to run a job on any number of CPUs, even on different physical machines. In order to use multiple machines, mpirun must have a list of available machines. This is usually in the form of a plain text file, with hosts8.6 listed one per line. mpirun refers to these files as machinefiles. Here is an example machinefile.
# "nodes" # Example machine file Node dummy.host.1.uchicago.edu # 1 dummy.host.2.uchicago.edu # 2 dummy.host.3.uchicago.edu # 3 dummy.host.4.uchicago.edu # 4 dummy.host.5.uchicago.edu # 5 dummy.host.6.uchicago.edu # 6 dummy.host.7.uchicago.edu # 7 dummy.host.8.uchicago.edu # 8
Here the # indicates the beginning of comment. Everything from the # to the end of line will be ignored by mpirun. Now that we have eight machines available, lets try running our example on more than one cpu. This time we'll use the time command to analyze the performance gain from use multiple CPUs.
[donour@host]~/mpi$ time mpirun -machinefile nodes -np 1 ./example pi = 3.141592655451890 real 0m15.274s user 0m14.930s sys 0m0.070s [donour@host]~/mpi$ time mpirun -machinefile nodes -np 2 ./example pi = 3.141592655451732 real 0m8.189s user 0m7.550s sys 0m0.060s [donour@host]~/mpi$ time mpirun -machinefile nodes -np 4 ./example pi = 3.141592655452444 real 0m5.709s user 0m3.980s sys 0m0.080s [donour@host]~/mpi$ time mpirun -machinefile nodes -np 8 ./example pi = 3.141592655452162 real 0m11.681s user 0m2.320s sys 0m0.190s [donour@host]~/mpi
|
Here we see strange results as we increase the number of CPUs. The runtime is longer with either CPUs than with two or four. Looking at the code we see that computation loop decomposes evenly and that communication is minimal. Therefore the program should scale very well. Indeed the program does scale well. However for the above tests, we never asserted that all the machines were the same speed. It turns out that last four hosts in the machinefile are considerably slower than the first four. This is somewhat counterintuitive as it may seem that adding more hardware could only make the program faster, but recall Amdahl's law. The total execution can never be faster than the time it takes for each worker to compute it's part. Adding slow CPUS can sometimes slow down the whole program.
MPIch also provides wrappers for Fortran 77 and Fortran 90 compilers. If these are available on your system, the wrappers will be called mpif77 and mpif90, respectively. The usage is similiar to mpicc.
FIXME: add fortran90 version of above example.
Since MPI is primarily a library for message passing, it follows that it's main constructs should be for communication. Consequently, one of the most important things to keep in mind when writing a program is how the computation will be split and how to reassemble the solution at the end.
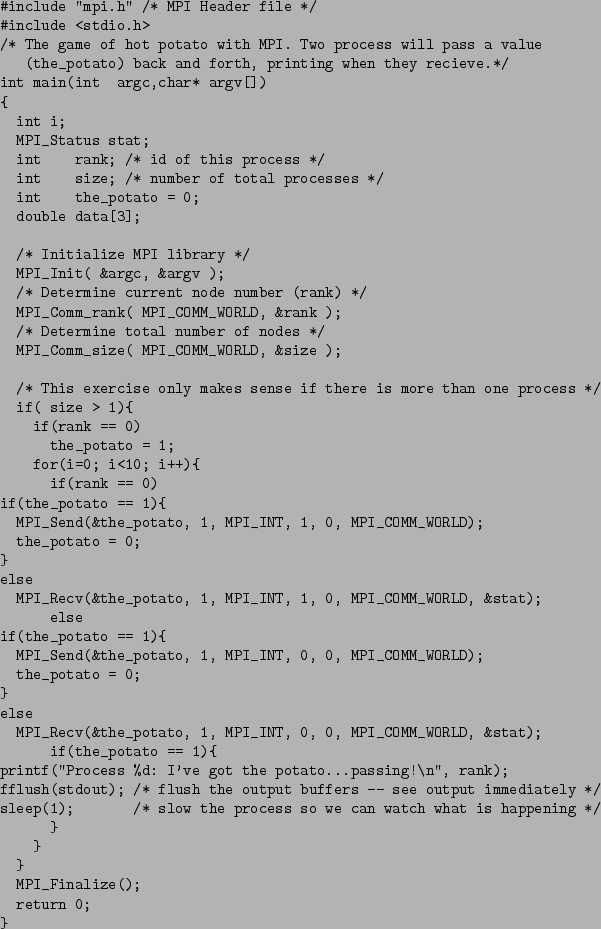
The simplest case of communcation is when one process has a piece of data, and another one needs it. This may be single number, a vector, or even a much more complicated structure like a C++ class or GSL matrix. For this, MPI provides two functions: MPI_Send and MPI_Recv. Naturally, the first sends a buffer of data and the latter recieves it.
To be completed.. .
To be completed...
Information Technology support is handled through the Social Science Computing Services group [http://ssdcs.uchicago.edu] and NSIT [http://nsit.uchicago.edu]. They can assist users with email and other general desktop computing issues.
An operating system is the piece of software that controls access to a computer's hardware and manages the other running programs. Operating systems provide basic interface mechanisms from which more complicated environments can be built (Graphical User Interfaces, shells, etc.). The operating system is in charge of program scheduling, resource allocation, and storage management on a computer.
Strictly speaking, the name UNIX refers to an operating system developed at Bell Labs during the 1970's. Since then, many compatible and similiar operating systems (Linux, BSD, Solaris) have emerged. The IEEE A.1 maintains a standard for these operating systems called Posix. For the purpose of this document, Unix will be used to refer to the broader range of Posix compliant operating systems. This crash course was written with Linux in mind, but it is also applicable to other Unices.
Each Unix user has a directory for storing their personal files. This directory usually has a name matching the user who owns it. It is called the user's home directory. This is the appropriate place to store configuration files, source code, and data.
Before using a Unix system you must log in. This requires a username and a password. It also requires somewhere to input your name and password so that the Unix system can verify your identity and establish a connection with the user (you). If you're sitting in front of the machine's terminal, this is easy. A prompt is provided. However, most people will want to connect to remote Unix machines. This can be accomplished in a number of ways.
Telnet is a protocol for connecting to remote machines using a simple text protocol. Nearly every Unix machine on the planet supports telnet connections, although most of their administrators do not allow them. Telnet is known to be very insecure and should be avoided if at all possible.
SSH is an alternative to telnet where both the login negotiation and all subsequent communications are encrypted. To connect using SSH, an ssh client is needed. These are freely available on the internet. Examples include the OpenSSH client for UnixA.2 and PuTTY for Windows.
[donour@host]~$ ssh altus The authenticity of host 'altus (192.168.0.1)' can't be established. RSA key fingerprint is 12:f9:0e:01:3a:86:8e:75:82:ef:db:27:24:de:eb:23. Are you sure you want to continue connecting (yes/no)? $
Answering yes to this questions allows you to continue and log into the host. OpenSSH then addes the hosts key to the file .ssh/known_hosts. Each subsequent time you log in, OpenSSH will check the identity of the remote host and compare it to the entry saved in known_hosts. If the remote host changes it's key, OpenSSH will alert you.
[donour@host]~$ ssh altus @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY! Someone could be eavesdropping on you right now (man-in-the-middle attack)! It is also possible that the RSA host key has just been changed. The fingerprint for the RSA key sent by the remote host is 22:f9:0e:01:3a:86:8e:75:82:ef:db:27:24:de:eb:23. Please contact your system administrator. Add correct host key in /home/donour/.ssh/known_hosts to get rid of this message. Offending key in /home/donour/.ssh/known_hosts:36 RSA host key for altus has changed and you have requested strict checking. Host key verification failed. [donour@host]~$
This indicates that the host you are trying to log into may not be the host you believe it is. This can be caused for a variety of reasons, the most common two are:
In either case, you should contact your system administrator to find out what is going on before continuing to use the host. To remove the warning (again, only after you have made certain the host is safe), simply delete the offending key from the known_hosts file.
Another purpose for encryption keys is to provide a more secure authentication mechanism than just a passwordA.4. Two files are needed for authentication; a public key and a private key. The public key can be freely distributed, published, etc. The private key should not be read by anyone else. To create these keys, use the program ssh-keygen.
[donour@host]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/donour/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/donour/.ssh/id_rsa. Your public key has been saved in /home/donour/.ssh/id_rsa.pub. The key fingerprint is: ea:bf:d0:d3:48:2a:71:66:df:ed:3a:bb:b8:0b:82:ee donour@athens [donour@host]$
For most users, the default settings should be fine. The empty password field allows the user to log in by simply having the private key (without typing a password). If you enter a password here, you will need to have the key and the password. Notice that two files were created: .ssh/id_rsa (this is the private key) and .ssh/id_rsa.pub (this is the public key). One more step is required before the key can be used for authenication. You must copy the public key to the host(s) you want to log into.
When you attempt to log into a machine that is running OpenSSH, the server checks a special file in your home directory called .ssh/authorized_keys. This file should contain the public keys (one per line) of all the hosts you want to log in from. So, to use the keys we just generated to log into a remote host, we have to copy the contents of .ssh/id_rsa.pub on the localhost to .ssh/authorized_keys on the remote host. If everything goes correctly, you can log into the remote host using your keys, without entering a password.
[donour@kentuck]~$ hostname host [donour@kentuck]~$ ssh altus [donour@altus]~$ hostname altus [donour@altus]~$
Every user of a Unix system has a user ID (UID) assoicated with them. This UID is a postive integerA.5. This UID is used for authenication (``Am I who I say I am?'') and authorization (``Can I do what I'm trying to do?''). Each UID is also associated with one or more Group IDs (GID), which are also postive integers. Several UID's can be associated with (``in'') the same group.
To make things easier for humans, every UID and GID also has a text name tied to it. Knowing these numbers tells you everything you need to know about your identity on the sytem. The command id displays your current identification.
[donour@host]~$ id uid=1001(donour) gid=100(users) groups=100(users),245(slocate) [donour@host]~$
This user's UID is 1001 and his corresponding username is donour. He is a member of the groups users (GID 100) and slocate (GID 245).
Shells are command interpreters. However, they are more than just a prompt for users to run commands. They provide an environment for controlling the whole computing system and for connecting programs and data together. At the shell users can run programs by typing their names. To logout, use the logout command.
All examples in this document will assume that the default shell is bashA.6 However, the same effects can be achieved using most other shells as well ( csh, ksh, etc.). Consult your local documentation if bash is not available.
Aside from running programs, the most common use of a shell is to navigate and manipulate files. Here are some common commands:
By design, Unix is a multitasking operating systems. This means that several programs can be running simultaneously. It would be wasteful to have a seperate shell open for every program running. Therefore the shell provides ways to control currently running jobs. A running instance of a program is called a process. For example: Netscape is a program, but when three people are using it simultaneously each running copy is a different process.
Environment Variables are name-value pairs that affect the behavior of your programs. They are one of the simplest ways of passing information to a program. For example: the variable PATH tells the shell the default location for programs. It is natural to call this collection of variables a user ``environment''. To display which variables are current set, use the env command.
[donour@athens donour]$ env PWD=/home/donour TZ=US/Central HOSTNAME=athens MANPATH=/opt/SUNWspro/man:/usr/local/man:/usr/man USER=donour MACHTYPE=sparc-sun-solaris2.9 LOGNAME=donour SHELL=/bin/bash OSTYPE=solaris2.9 HOME=/home/donour TERM=xterm PATH=/home/donour/bin:/usr/local/bin:/usr/bin _=/usr/bin/env [donour@athens donour]$
As you can see, this user has many environment variables set. In fact it's not unusual for user to regularly set several dozen enironment variables. Let's look at the PATH variable more closely. Notice that it contains several directories (/home/donour/bin, /usr/local/bin, and /usr/bin) each seperated by colon. When you try to run a program from the shell, it will look in all of these places. The command export allows you to set environment variables. Suppose you want to be able to run programs from the directory /opt/bin as well as the ones seen above. Use the command:
export PATH=/home/donour/bin:/usr/local/bin:/usr/bin:/opt/bin
Environment variables can be accessed on the shell's commandline by prefixing their name with a $. So a shorter way of adding something to the PATH variable would be to use: export PATH=$PATH:/newpath. This takes everything from the old path, adds /newpath and resets the PATH variable.
One of the oldest adages of the Unix is world is ``Everything is a file.'' Many new users face difficulties when trying to understand Unix filesystem permissions, which are the oldest and most universal forms of system security. Controlling access to files provides a fairly complete way to control access to the whole system.
In Unix, there are three ways to access a file: reading, writing, and executing. For a normal file, the meaning of these terms is straightforward. Reading a file means viewing its contents, writing a file means changing its contents, and executing a file means using the file as a programA.7. Directories are a special type of file, and the meaning becomes less obvious. Reading a directory consists of viewing its contentsA.8. Writing a directory allows the creation of new files in that directory. Executing a directory allows a user to set that directory as his/her current working directory. This is needed if that user wishes to access any subdirectories and is required for reading or writing. These three modes are can be set independantly and are usually referenced by shortened names: r,w, and x.
Every file as an owner (UID) and a group (gid) associated with it. For every file, there are three distinct sets of users.
These three sets are generally shortened to user, group, and other. Combine this with the three permission modes and there are nine different permission states which must be set independently. You can direct the ls command to display these modes.
[donour@host]~/tmp/threads$ ls -l total 28 drwxr-xr-x 2 donour users 4096 Nov 11 14:50 . drwxr-xr-x 5 donour users 4096 Nov 11 14:40 .. -rwxr-xr-x 1 donour users 9839 Aug 25 11:16 run -rw-r--r-- 1 donour users 1974 Aug 21 13:27 tsort.c -rw-r--r-- 1 donour users 1023 Aug 13 16:01 tsort.h [donour@host]~/tmp/threads$
The first column of output shows the permission modes and can look quite intimidating at first, but is actually quite easy to parse. The first item indicates whether a file is a directory or a regular file. The next three bits are permissions for the owner, the next three for group, and the next three for others. As you can see, this directory contains two regular files (tsort.c, tsort.h), one program (run), and two directories(., ..)A.9.
To change a file's permissions several commands are available:
The Unix shell provides a simple way to redirect information from a file to a program's input or output. This allows users to easily save the output from a program, suppress error messages, or even link multiple programs together.
Normal Unix processes have three special files open at all timesA.10: stdin, stdout, stderr. stdin is the standard input file. By default, it is connected to the keyboard. stdout is the standard output file. It is attached to the terminal or screen in which the programming is running. stderr is the stand error file. It is attached to the programs screen or terminal as well, but is meant for printing error mesgs. It is often desirable to have an extra conduit for error mesgs rather than providing them inline with a programs normal output.
Consider the pipe example from the previous section. Lets replace the date command with a system-wide find. Our new command will be find / | wc. This will count the number of words in all the filenames on the entire system. However, some files will be unavailable to us; other user's home directories, system configuration files, etc. These errors will be printed through stderr. Because the pipe (|) only redirects stdout, wc will not count the error messages.
[donour@athens]~$ find / | wc find: /lost+found: Permission denied find: /home/lost+found: Permission denied find: /root: Permission denied ... <output truncated> ... find: /mnt/floppy: Permission denied 506212 507461 27393009 [donour@athens]~$
While there exist a plethora of Integrated Developement Environments (IDE), old-fashioned text editors are still the dominant way to write programs. There are many powerful and mature editors available on Unix.
Emacs is not an editor. Emacs is a way of thinking about the world, and as such is a way of thinking about editors. The process of editing is Emacs, but Emacs is more than the process of Editing. When you ask what Emacs does, you are asking a question with no answer, because Emacs doesn't do, it is done to. Emacs just is. ... I hope this makes things clearer. -Scott Dorsey
The Emacs editor is a world unto itself. Every part of the interface is configurable. Furthermore Emacs includes an integrated Lisp interpreter to control and customize its behavior. If that doesn't satisfy, the source is available for free. A quick introduction is provided here, but the complete reference is available in the manual[2].
Run Emacs with the command: emacs. The following table of commands should get the new user started.
|
To be completed...
Screen is a window manager for the Unix terminal. Screen enables you to have several programs (shells, simulations, etc.) running inside a single terminal. You can then switch between them in same way you switch between applications in windowed environment. You can even detach your Screen session, log off, and reattach it when you log back in. All the jobs started inside the Screen will continue to run when you are logged off.
|
Screen is a very good way of running jobs without maintaining a connection to the server. Consider the following example. You have a program estimate that you want to run overnight. You want to start the job during the afternoon from your workstation, check its progress from home on your laptop, then check its progress again the next day from your workstation.
[donour@host] ssh athens.src.uchicago.edu
Last login: Tue Oct 21 09:21:11 2003 from donour.spc.uchi
Sun Microsystems Inc. SunOS 5.9 Generic May 2002
[donour@athens donour]
[donour@athens donour] screenThe screen program clears the screen, launches a new shell then hands control over to the user.
[donour@athens donour] ./estimate
[donour@athens donour] screen
[detached]
[donour@athens donour] logout
Connection to athens.src.uchicago.edu closed.
[donour@host]
Now the program estimate is running inside the screen on the server
without any outside connection.
[donour@host] ssh athens.src.uchicago.edu Last login: Tue Oct 21 09:21:11 2003 from donour.spc.uchi Sun Microsystems Inc. SunOS 5.9 Generic May 2002 [donour@athens donour] screen -rThe screen session is now reattached.
[donour@athens donour] ./estimate model 0 done model 1 done
Unix provides online manual pages for most of its software. These
manuals can be accessed using the program man. For example:
[donour@athens] $ man uptime
This command displays the manual for the program uptime, which
reports how long the system has been running without a restart. The
manual explains things such as what input is valid for a program and
what flags are available. Known bugs are often listed there as are
usage tips and related software packages.Man pages also exist for many
C library functions A.12.
[donour@athens] $ man malloc
This particular page is for the C memory allocator, malloc(). Unix users should consult the man pages early and often. The are the usually the quickest reference for system functionality and provide pointers to related software and documentation. Even experienced users refer to them every day.
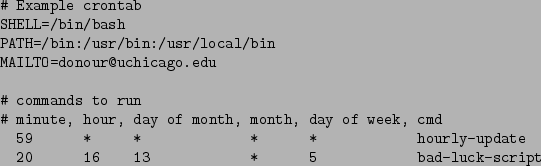
Cron is a command scheduler that allows you to automatically run commands at specified times, whether you are logged in or not. Timekeeping and program execution is handled by a system service, all you need to provide is a table of commands and when they should be run (a cron table). Because the location of these tables can vary from system to system, a special program is provided to create them: crontab.
To edit your crontab, use the command: crontab -e. crontab will open the text editor defined the in the environment variableA.13 EDITOR. To edit his crontab, the author executes the following:
[donour@host]$ export EDITOR=emacs [donour@host]$ crontab -e
A crontab file consists of two important parts, environment
descriptions and job definitions. Consider the following example:
Lines beginning with # are considered comments and are ignored by cron. Notice that the first three lines specify environment variables that are key to running processes.
The next two lines are fairly cryptic. They specify what programs to run and when, one per line. Each line consists of six fields. The first five are time scheduling information, the last is the command to run. The five time fields are:
A wildcard, *, matches all values for that field. Putting this
all together, the first line instructs cron to run the program hourly-update at the 59 minutes after the hour, every hour. The
next line instructs cron to run bad-luck-script at 4:20 ![]() every friday the
13
every friday the
13![]()
The Regenstein Maclab holds introductory Unix sessions every quarter. More information is available at [http://www.maclab.cs.uchicago.edu/minicourse.html].
The Department of Computer Science offers a number of courses in scientific computing and parallel programming that may aid researchers. The latest course offerings are always available at their website [http://www.cs.uchicago.edu/courses]. Courses that have interested researchers in the past include:
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 1 guide.tex
The translation was initiated by on 2004-10-20