« Things to read while the simulator runs; part 4 | Main | The kaleidoscope in our eyes »
March 21, 2007
Structuring science; or: quantifying navel-gazing and self-worth
Like most humans, scientists are prone to be fascinated by themselves, particularly in large groups, or when they need to brag to each other about their relative importance. I want to hit both topics, but let me start with the latter.
In many ways, the current academic publishing system aggravates some of the worst behavior scientists can exhibit (with respect to doing good science). For instance, the payoff for getting an article published in one of a few specific high-profile journals [1] is such that - dare I say it - weak-minded scientists may overlook questionable scientific practices, make overly optimistic interpretations the significance of their results, or otherwise mislead the reviewers about the quality of the science [2,3].
While my sympathies lie strongly with my academic friends who want to burn the whole academic publishing system to the ground in a fit of revolutionary vigor, I'm reluctant to actually do so. That is, I suppose that, at this point, I'm willing to make this faustian bargain for the time I save by getting a quick and dirty idea of a person's academic work by looking at the set of journals in which they're published [4]. If only I were a more virtuous person [5] - I would then read each paper thoroughly, at first ignoring the author list, in order to gauge its quality and significance, and, when it was outside of my field, I would recuse myself from the decision entirely or seek out a knowledgeable expert.
Which brings me to one of the main points of this post - impact factors - and how horrible they are [6]. Impact factors are supposed to give a rough measure of the scientific community's appraisal of the quality of a journal, and, by extension, the articles that appear in that journal. Basically, it's the the average number of citations received by an article (as tracked by the official arbiter of impact, ISI/Thompson), divided by the number of articles published in that journal, or something. So, obviously review journals have a huge impact because they publish only a few papers that are inevitably cited by everyone. The problem with this proxy for significance is that it assumes that all fields have similar citation patterns and that all fields are roughly the same size, neither of which is even remotely true. These assumptions explain why a middling paper in a medical journal seems to have a larger impact than a very good paper in, say, physics - the number of people publishing in medicine is about an order of magnitude greater than the number of physicists, and the number of references per paper is larger, too. When these bibliometrics are used in hiring and funding decisions, or even decisions about how to do, how to present, where to submit, and how hard to fight for your research, suddenly these quirks start driving the behavior of science itself, rather than the other way around.
Enter eigenfactor (from Carl Bergstrom's lab), a way of estimating journal impact that uses the same ideas that Google (or, more rightly, PageRank, or, even more rightly, A. A. Markov) uses to give accurate search results. The formulation of a journal's significance in terms of Markov chains is significantly better than impact factors, and is significantly more objective than the ranking we store in our heads. For instance, this method captures our intuitive notion about the significance of review articles - that is, they may garner many citations by defining the standard practices and results of an area, but they consequently cite very many articles to so, and thus their significance is moderated. But, this obsession with bibliometrics as a proxy for scientific quality is still dangerous, as some papers are highly cited because they are not good science! (tips to Cosma Shalizi, and to Suresh)
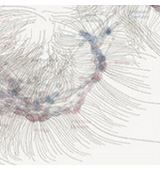 The other point I wanted to mention in this post is the idea of mapping the structure of science. Mapping networks is a topic I have a little experience with, and I feel comfortable saying that your mapping tools have a strong impact on the kind, and quality, of conclusions you make about that structure. But, if all we're interested in is making pretty pictures, have at it! Seed Magazine has a nice story about a map of science constructed from citation patterns of roughly 800,000 articles [7] (that's a small piece of it to the left; pretty). Unsurprisingly, you can see that certain fields dominate this landscape, and I'm sure that some of that dominance is due to the same problems with impact factors that I mentioned above, such as using absolute activity and other first-order measures of impact, rather than integrating over the entire structure. Of course, there's some usefulness in looking at even dumb measures, so long as you remember what they leave out. (tip to Slashdot)
The other point I wanted to mention in this post is the idea of mapping the structure of science. Mapping networks is a topic I have a little experience with, and I feel comfortable saying that your mapping tools have a strong impact on the kind, and quality, of conclusions you make about that structure. But, if all we're interested in is making pretty pictures, have at it! Seed Magazine has a nice story about a map of science constructed from citation patterns of roughly 800,000 articles [7] (that's a small piece of it to the left; pretty). Unsurprisingly, you can see that certain fields dominate this landscape, and I'm sure that some of that dominance is due to the same problems with impact factors that I mentioned above, such as using absolute activity and other first-order measures of impact, rather than integrating over the entire structure. Of course, there's some usefulness in looking at even dumb measures, so long as you remember what they leave out. (tip to Slashdot)
-----
[1] I suppose the best examples of this kind of venue are the so-called vanity journals like Nature and Science.
[2] The ideal, of course, is a very staid approach to research, in which the researcher never considers the twin dicta of tenure: publish-or-perish and get-grants-or-perish, or the social payoff (I'm specifically thinking of prestige and attention from the media) for certain kinds of results. Oh that life were so perfect, and science so insulated from the messiness of human vice! Instead, we get bouts of irrational exuberance like polywater and other forms of pathological science. Fortunately, there can be a scientific payoff for invalidating such high-profile claims, and this (eventual) self-correcting tendency is both one of the saving graces of scientific culture, and one of the things that distinguishes it from non-sciences.
[3] There have been a couple of high-profile cases of this kind of behavior in the scientific press over the past few years. The whole cloning fiasco over Hwang Woo-Suk's work is probably the best known of these (for instance, here).
[4] I suppose you could get a similar idea by looking at the institutions listed on the c.v., but this is probably even less accurate than the list of journals.
[5] To be fair, pre-print systems like arXiv are extremely useful (and novel) in that force us to be more virtuous about evaluating the quality of individual papers. Without the journal tag to (mis)lead, we're left having to evaluate papers by other criteria, such as the abstract, or - gasp! - the paper itself. (I imagine the author list is also frequently used.) I actually quite like this way of learning about papers, because I fully believe that our vague ranking of academic journals is so firmly ingrained in our brains, that it strongly biases our opinions of papers we read. "Oh, this appeared in Nature, it must be good!" Bollocks.
[6] The h-index, or Hirsch number is problematic for similar reasons. A less problematic version would be to integrate over the whole network of citations, rather than simply looking at first-order citation patterns. If we would only truly embrace the arbitrariness of these measures, we would all measure our worth by our Erdos numbers, or some other demigod-like being.
[7] The people who created the map are essentially giving away large versions of it to anyone willing to pay shipping and handling.
posted March 21, 2007 11:07 AM in Scientifically Speaking | permalink