« January 2011 | Main | March 2011 »
February 18, 2011
1000 Citations?
Today I'm going to admit something embarrassing, but something I suspect many academics do, especially now that it's so easy: I track my citation counts. It's always nice to see the numbers increase, but it also lets me keep up with which communities are reading my papers. Naturally, some papers do much better than others in picking up citations [1]. One that's been surprisingly successful is my paper with Cosma Shalizi and Mark Newman on power-law distributions in empirical data [2], which crossed 500 citations on Google Scholar earlier this year. Here's what the citation time series looks like [3]:
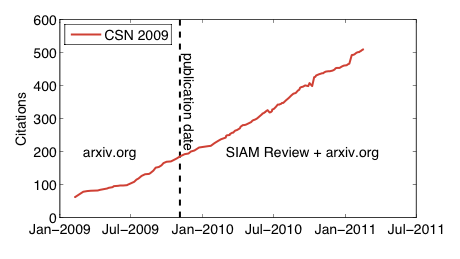
I've marked the online publication date (4 November 2009) in SIAM Review in the figure with the black dashed line. Notably, the trajectory seems completely unperturbed by this event, suggesting that perhaps most people who were finding the paper, were finding it through the arxiv, where it was posted in October 2007.
Given its already enormous citation count, with this data in hand, can we predict when it will pass the mind-boggling 1000 citation mark? The answer is yes, although we'll have to wait to see if the prediction is correct. [4]
Derek de Solla Price, the father of modern bibliometrics and the original discoverer of the preferential attachment mechanism for citation networks, tells us that the growth rate of citations is proportional to the number of citations a paper already has. Testing this assumption is trickier than it sounds. At the whole-citation-network level, the prediction of this assumption is a distribution of citations that has a power-law tail [5]. There have been a few attempts to test the microscopic assumption itself, again on a corpus of papers, and one of my favorites is in a 2005 paper in Physics Today by Sid Redner [6]. Redner analyzed 110 years of citation statistics from the Physical Review journals, and he calculated the attachment rates for groups of papers by first counting all the citations they received in some window of time [t,t+dt] and then counting the number of citations each of those papers received in a given subsequent year T. He then plotted the new citations in year T versus the total citations in the window, and observed that the function was remarkably linear, indicating that the proportional attachment assumption is actually pretty reasonable.
But, I haven't seen anyone try to test the proportional growth assumption on an individual paper, and perhaps for good reason. The model is grossly simplified: it ignores factors like the quality or importance of the paper, the fame of the authors, the fame of the journal, the influence of the peer review process, the paper’s topic, etc. In fact, the model ignores everything about the papers themselves except for its citation count. If we consider very many papers, it seems potentially plausible that these things should average out in some way. But for a single paper, surely these factors are important.
Maybe, but let's ignore them for now. For the CSN_2009 paper, let's mimic what Redner did to estimate the attachment rate: we choose some window length dt, divide up the 739 days of data into blocks each of dt days, and plot the number of citations at the beginning of a window versus the number of new citations the paper acquires over the next dt days. Here's the result, for a window length of 20 days:
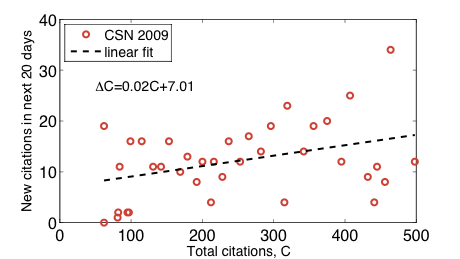
along with a simple linear fit to the scatter. Surprisingly, the positive slope suggests that the citation rate has indeed been increasing (roughly linearly) with total citation count, which in turn suggests that proportional growth is potentially a reasonable model of the citation history of this one specific paper. It also suggests that people are citing our paper not because it's a good paper, but because it's a highly cited paper. After all, proportional growth is a model of popularity not quality. (Actually, the very small value of the coefficient suggests that this might be a spurious result; see [7] below.)
This linear fit to the attachment rates is, effectively, a parametric proportional growth model, i.e., the coefficients allow us to estimate the number of new citations the paper will acquire in the next 20 days, as a function of the current citation count. Integrating this attachment rate over time allows us to make a projection of the paper's citation trajectory, which allows us to predict the date at which the paper will cross 1000 citations. Since the window size dt is an arbitrary parameter, and it's not at all clear how to choose the best value for it, instead we'll just make a set of projections, one for each value of dt. Here's the result:
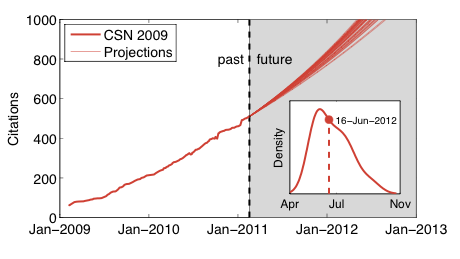
with the inset showing the smoothed distribution of predicted dates that the citation count will cross 1000. All of the predicted crossing dates fall in 2012, but vary based on the different fitted attachment rate models. The median date is 16 June 2012, which is slightly later than the mode at 29 May (this seems reasonable given the non-linear nature of the growth model); the 5 and 95% quantiles are at 1 May and 31 August.
So, there you have it, a prediction that CSN_2009 will cross 1000 citations in 14-18 months, and most likely in 15-16 months. [7] If I'm right, someone want to buy me a beer (or maybe a mug) to celebrate?
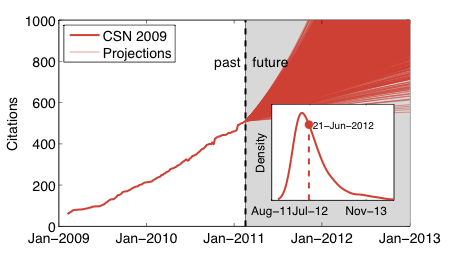
Update 18 Feb. 2011: After some gentle nudging from Cosma, I ran a simulation that better handles the uncertainty in estimating the attachment model; the improvement was to bootstrap the measured attachment rates before fitting the model, and then use that larger set of estimates to generate the distribution of crossing dates. Below is the result. The difference in the envelope of projections is noticeable, with a much wider range of crossing times for 1000 citations (a few trajectories never cross 1000), but the overprinting is deceptive. The inset shows that the distribution is mainly just wider. Comfortably, the middle of the distribution is about where it was before, with the median prediction at 12 June 2012 and the mode at 21 April 2012. The variance, as expected, is much larger, with the 5-95% quantiles now ranging from 11 Jan. 2012 all the way to 29 Nov. 2013.
-----
[1] One reason to distrust raw citation counts is that a citation doesn't provide any context for how people cite the paper. Some contexts include "everyone else cites this paper and so are we", "this is background material actually relevant to our paper", "this paper is wrong, wrong, wrong", "studies exist", "this paper mentions, in a footnote, something we care about", "we've read this paper, thought about it deeply and are genuinely influenced by it", among many others.
[2] It's hard not to be pleased with this, although there is still work to be done in fixing the power-law literature: I still regularly see new articles on the arxiv or in print claiming to see power-law distributions in some empirical data and using linear-regression to support the claim, or using maximum likelihood to estimate the exponent but not calculating a p-value or doing the likelihood ratio test.
[3] I started tracking this data via Google Scholar about two years ago, so I'm missing the earlier part of the time series. Unfortunately, Google Scholar does not allow you to recover the lost data. In principle other citation services like ISI Web of Science would, since every publication they track includes its pub date. There are also other differences. Google Scholar tends to pick up peer-reviewed conference publications (important in computer science) while ISI Web of Science tracks only journals (and not even all of them, although it does get very many). Google Scholar also picks up other types of "publications" that ISI omits, including tech reports, pre-prints, etc., which some people think shouldn't count. And, sometimes Google Scholar takes citations away, perhaps because it can't find the citing document anymore or because the Google Scholar team has tweaked their algorithms. In the time series above, you can spot these dips, which would not appear in the corresponding ISI time series.
[4] "It's hard to make predictions, especially about the future," a saying attributed to many people, including Yogi Berra, Niels Bohr and Mark Twain.
[5] In fact, the precise form of the distribution is known. For Price's original model, which includes the more recent Barabasi-Albert model as a special case, the distribution follows the ratio of two Beta functions, and is known as the Yule-Simon distribution. This distribution has a power-law tail, and is named after Udny Yule and Herbert Simon, whose interest in preferential attachment predated Price's own interest, even though they weren't thinking about citations or networks. I believe Simon was the first to derive the limiting distribution exactly for the general model, in 1955. If you're interested in the history, math or data, I gave a lecture on this topic last semester in my topics course.
[6] S. Redner, "Citation Statistics from 110 years of Physical Review" Physics Today 58, 49 (2005).
[7] There are other ways we could arrive at a prediction, and better ways to handle the uncertainty in the modeling. For instance, none of the projections accounted for uncertainty in the parameters estimated from the attachment rate data, and including that uncertainty would lead to a distribution of predictions for a particular projection. Doing the same trick with the window length would probably lead to higher variance in the distribution of prediction dates, and might even shift the median date. (Computing the distribution of predicted dates over the different window lengths does account for some amount of the uncertainty, but not all of it.)
Another possibility is to be completely non-parametric about the attachment function's form, although additional questions would need to be answered about how to do a principled extrapolation of the attachment function into the unobserved citation count region.
Still another way would be to dispense with the proportional growth model completely and instead consider something like the daily attachment rate, projected forward in time. Surprisingly, this technique yields a similar prediction to the proportional growth model, probably because the non-linearity in the growth rate is relatively modest, so these models would only diverge on long time scales. This fact is a little bit like a model-comparison test, and suggests that at this point, it's unclear whether proportional growth is actually the better model of this paper's citation trajectory.
posted February 18, 2011 08:35 AM in Self Referential | permalink | Comments (5)
February 13, 2011
Proximate vs. Ultimate Causes
Jon Wilkins, a former colleague of mine at the Santa Fe Institute, has discovered a new talent: writing web comics. [1] Using the clever comic-strip generator framework provided by Strip Generator, he's begun producing comics that cleverly explain important ideas in evolutionary biology. In his latest comic, Jon explains the difference between proximate and ultimate causes, a distinction the US media seems unaware of, as evidenced by their irritating fawning over the role of social media like Twitter, Facebook, etc. in the recent popular uprisings in the Middle East. Please keep them coming, Jon.

-----
[1] Jon has several other talents worth mentioning: he's an evolutionary biologist, an award-winning poet, a consumer of macroeconomic quantities of coffee as well as a genuinely nice guy.
posted February 13, 2011 04:58 PM in Scientifically Speaking | permalink | Comments (0)
February 05, 2011
Design and Analysis of Algorithms (CSCI 5454)
This semester, I'm teaching a new course (for me) on the design, analysis and evaluation of computer algorithms. This is a graduate-level course and covers a lot of standard material in algorithms. My hope, however, is to also show the students how different strategies for algorithm design work (and sometimes don't work) and to introduce them to a number of more advanced topics and algorithms they might encounter out in industry.
For those of you interested in following along, here's a list of my lecture notes and the topics I've covered. I'll update this entry with the rest of the lectures, once they're up on the course webpage.
CSCI 5454 Design and Analysis of Algorithms
Algorithms are the heart of computer science, and their essential nature is to automate some aspect of the collecting, organizing and processing of information. Today, information of all kinds is increasingly available in enormous quantities. However, our ability to make sense of all this information, to manage, organize and search it, and to use it for practical purposes, e.g., self-driving cars, adaptive computation, search algorithms for the Internet or for social networks, artificial intelligence, and many scientific applications, relies on the design of efficient algorithms, that is, algorithms that are fast, use little memory and provide guarantees on their performance.
This graduate-level course will cover a selection of topics related to algorithm design and analysis. Topics will include divide and conquer algorithms, greedy algorithms, graph algorithms, algorithms for social networks, computational biology, optimization algorithms, randomized data structures and their analysis. We will not cover any of these topics exhaustively. Rather, the focus will be on algorithmic thinking, efficient solutions to practical problems and understanding algorithm performance. Advanced topics will cover a selection of modern algorithms, many of which come from real-world applications.
Lecture 0: Why algorithms, and an example
Lecture 1: The divide and conquer strategy, quicksort and recurrence relations
Lecture 2: Randomized quicksort and probabilistic analysis
Lecture 3: Randomized data structures and skip lists
Lecture 4: Randomized data structures, hash tables, the Birthday Paradox and the Coupon Collector problem
Lecture 5: The greedy strategy, linear storage media and Huffman codes
Lecture 6: Graphs and networks, graph algorithms, search-trees
Lecture 7: Single-source shortest path algorithms and Google Maps
Lecture 8: Minimum spanning trees
Lecture 9: Graph clustering and modularity maximization
Lecture 10: Maximum flows and minimum cuts
Lecture 11: Phylogenetic trees and parsimony
Lecture 12: Averaging trees
Lecture 13: Optimization, simulated annealing
Lecture 14: Stable matchings (student lecture)
Lecture 15: Disjoint sets and union find (student lecture)
Lecture 16: Sequence alignment (student lecture)
Lecture 17: Byzantine agreement (student lecture)
Lecture 18: Linear programming and the simplex algorithm (student lecture)
Lecture 19: Expectation-maximization (student lecture)
Lecture 20: Cake cutting and fair division (student lecture)
Lecture 21: Approximation algorithms (student lecture)
Lecture 22: Link prediction in social networks (student lecture)
Lecture 23: Sudoku puzzles and backtracking algorithms (student lecture)
posted February 5, 2011 09:36 AM in Teaching | permalink | Comments (0)
February 02, 2011
Whither computational paleobiology?
This week I'm in Washington DC, hanging out at the Smithsonian (aka the National Museum of Natural History) with paleontologists, paleobiologists, paleobotanists, palaeoentomologist, geochronographers, geochemists, macrostratigraphers and other types of rock scientists. The meeting is an NSF-sponsored workshop on the Deep Time Earth-Life Observatory Network (DETELON) project, which is a community effort to persuade NSF to fund large-ish interdisciplinary groups of scientists exploring questions about earth-life system dynamics and processes using data drawn from deep time (i.e., the fossil record).
One of the motivations here is the possibility to draw many different skill sets and data sources together in a synergistic way to shed new light on fundamental questions about how the biosphere interacts with (i.e., drives and is driven by) geological processes and how it works at the large scale, potentially in ways that might be relevant to understanding the changing biosphere today. My role in all this is to represent the potential of mathematical and computational modeling, especially of biotic processes.
I like this idea. Paleobiology is a wonderfully fascinating field, not just because it involves studying fossils (and dinosaurs; who doesn't love dinosaurs?), but also because it's a field rich with interesting puzzles. Surprisingly, the fossil record, or rather, the geological record (which includes things that are not strictly fossils), is incredibly rich, and the paleo folks have become very sophisticated in extracting information from it. Like many other sciences, they're now experiencing a data glut, brought on by the combination of several hundred years of hard work, a large community of data collectors and museums, along with computers and other modern technologies that make extracting, measuring and storing the data easier to do at scale. And, they're building large, central data repositories (for instance, this one and this one), which span the entire globe and all of time. What's lacking in many ways is the set of tools that can allow the field to automatically extract knowledge and build models around these big data bases in novel ways.
Enter "computational paleobiology", which draws on the tools and methods of computer science (and statistics and machine learning and physics) and the questions of paleobiology, ecology, macroevolution, etc. At this point, there aren't many people who would call themselves a computational paleobiologist (or computational paleo-anything), which is unfortunate. But, if you think evolution and fossils are cool, if you like data with interesting stories, if you like developing clever algorithms for hard inference problems or if you like developing mathematical or computational models for complex systems, if you like having an impact on real scientific questions, and if you like a wide-open field, then I think this might be the field for you.
posted February 2, 2011 08:26 PM in Interdisciplinarity | permalink | Comments (6)